
Sweat dedicated GPU clusters to beat cloud on cost
Over the past year, demand for GPUs to train generative AI models has soared. Some organizations have invested in GPU clusters costing millions of dollars for this purpose. Cloud services offered by the major hyperscalers and a new wave of GPU-focused cloud providers deliver an alternative to dedicated infrastructure for those unwilling, or unable, to purchase their own GPU clusters.
There are many factors affecting the choice between dedicated and cloud-based GPUs. Among these are the ability to power and cool high density GPU clusters in a colocation facility or enterprise, the availability of relevant skills, and data sovereignty. But often, it is an economic decision. Dedicated infrastructure requires significant capital expenditure that not all companies can raise. Furthermore, many organizations are only just beginning to understand how (and if) they can use AI to create value. An investment in dedicated equipment for AI is a considerable risk, considering its uncertain future.
In contrast, cloud services can be consumed by the hour with no commitment or reservation required (although this is changing in some cases as cloud providers struggle to supply enough resources to meet demand). Companies can experiment with AI in the public cloud, eventually developing full-featured AI applications without making significant upfront investments, instead paying by the unit.
Ultimately, the public cloud consumption model allows customers to change their mind without financial consequence, by terminating resources if they are not needed and vice versa. Such flexibility is not possible when a big investment has been made in dedicated infrastructure.
Although the cloud may be more flexible than dedicated equipment, it is not necessarily cheaper. The cheapest choice depends on how the hardware is used. To beat the cloud on cost, dedicated equipment must be sweated — that is, used to its fullest potential — to obtain a maximum return on investment.
Those organizations that fail to sweat their infrastructure face higher costs. A dedicated cluster with a utilization of 40% is 25% cheaper per unit than cloud, but a utilization of just 8% makes dedicated infrastructure four times the price of cloud per unit.
Unit cost comparisons
Unit pricing is inherently built into the public cloud’s operating model: customers are charged per virtual machine, unit of storage or other consumption metric. Cloud users can purchase units spontaneously and delete them when needed. Since the provider is responsible for managing the capacity of the underlying hardware, cloud users are unaffected by how many servers the provider has — or how well they are utilized.
Dedicated equipment purchased with capital is not usually considered in terms of consumption units. However, unit costs are important because they help determine the potential return on an investment or purchase.
To compare the cost of dedicated equipment against the cost of cloud infrastructure, the total capital and operating expenses associated with dedicated equipment must be broken out into unit costs. These unit costs reflect how much a theoretical buyer would need to pay (per consumed unit) for the capital investment and operating costs to be fully repaid.
This concept is best explained hypothetically. Consider a server containing two CPUs. The server is only expected to be in service for a year. Many departments share the server, consuming units of CPU months (i.e., accessing a CPU for one month). There are 24 CPU months in a year (two CPUs x 12 months). Table 1 calculates each CPU month’s unit cost, comparing whether the server is highly utilized over its life or only partly utilized.
Table 1 Example unit cost calculations

Table 1 shows how utilization impacts the unit cost. Greater utilization equals a lower unit cost, as the investment delivers more units of value-adding capability. Lower utilization equals a higher unit cost, as the same investment delivers fewer units.
Note that utilization in this context means the average utilization across all servers, even those that are sitting idle. If the organization has purchased 10 servers in an AI cluster, but only one is being used, the average utilization is just 10%; the unused servers are wasted investments.
Dedicated infrastructure versus public cloud
The previous example shows a hypothetical scenario to demonstrate unit costs. Figure 1 shows a real unit cost comparison of Nvidia DGX H100 nodes hosted in a North Virginia (US) colocation facility against an equivalent cloud instance, averaged with pricing data from AWS, Google Cloud, Microsoft Azure, CoreWeave, Lambda Labs and Nebius (collected in January 2025). Colocation costs reflected in this calculation include power, space and server capital as described in Table 3 (later in this report). Dedicated unit costs are the same regardless of the number of DGX servers installed in a cluster. Notably, the price between the hyperscalers and smaller GPU providers varies substantially (Uptime will publish a future report on this topic).
Figure 1 Variation in cost per server-hour by average cluster utilization over server lifetime
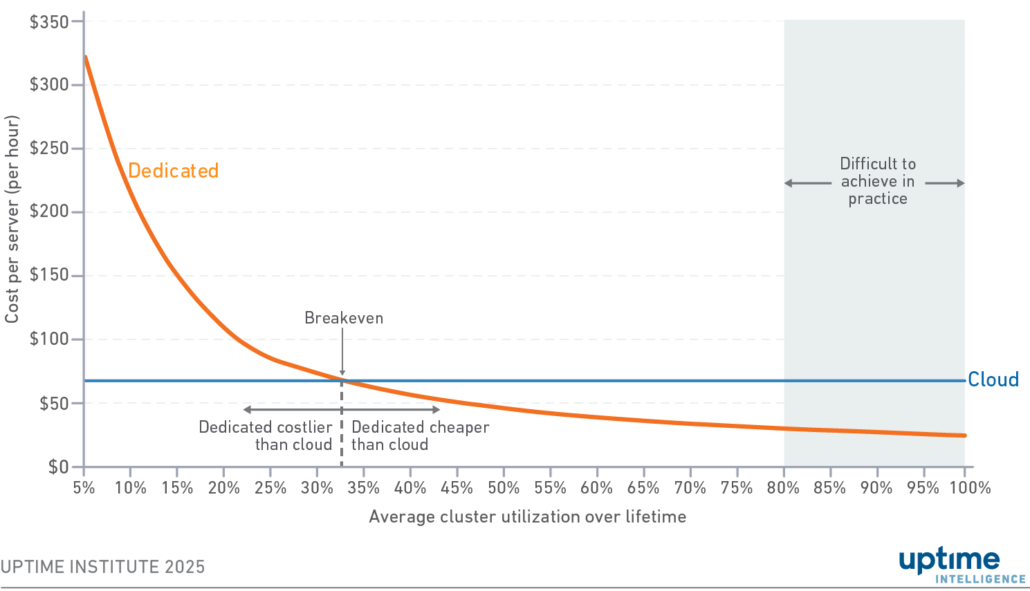
In Figure 1, the unit costs of cloud instances are constant because users buy instances using a per-unit model. The unit costs for the dedicated infrastructure vary with utilization.
Note that this report does not provide forensic analysis applicable to all scenarios, but rather illustrates how utilization is the key metric in on-premises versus cloud comparisons.
Dedicated is cheaper at scale
According to Figure 1, there is a breakeven point at 33% where dedicated infrastructure becomes cheaper per unit than public cloud. This breakeven means that over the amortization period, a third of the cluster’s capacity must be consumed for it to be cheaper than the cloud. The percentage may seem low, but it might be challenging to achieve in practice due to a multitude of factors such as the size of the model, network architecture and choice of software (Uptime will publish a future report explaining these factors).
Table 2 shows two different scenarios for training. In one scenario, a model is fine-tuned every quarter; in the other, the same model is fully retrained every other month.
Table 2 How training cycles impact utilization

When the dedicated cluster is being used for regular retraining, utilization increases, thereby lowering unit costs. However, when the cluster is only occasionally fine-tuning the model, utilization decreases, increasing unit costs.
In the occasional fine-tuning scenario, utilization of the dedicated infrastructure is just 8%. Using the dedicated equipment for an hour costs $250, compared with $66 for cloud, a cost increase of almost 300%. However, in the regular retraining scenario, the server has been used 40% of its lifetime, thereby undercutting the cloud on price ($50 versus $66 is a 25% cost saving).
Regular retraining would not necessarily improve the model’s performance enough to justify the increased expenditure.
Asymmetric risk
The cost impact of failing to meet the breakeven is greater than the benefit usually gained by doing so. In Figure 2, a dedicated cluster utilized 10 percentage points over the threshold makes a $16 saving per unit compared with the public cloud. But if an enterprise has been overly optimistic in its forecast, and misses the breakeven by 10 percentage points, it could have saved $30 by using public cloud.
Figure 2 Variation in unit costs by utilization, focusing on asymmetric risk
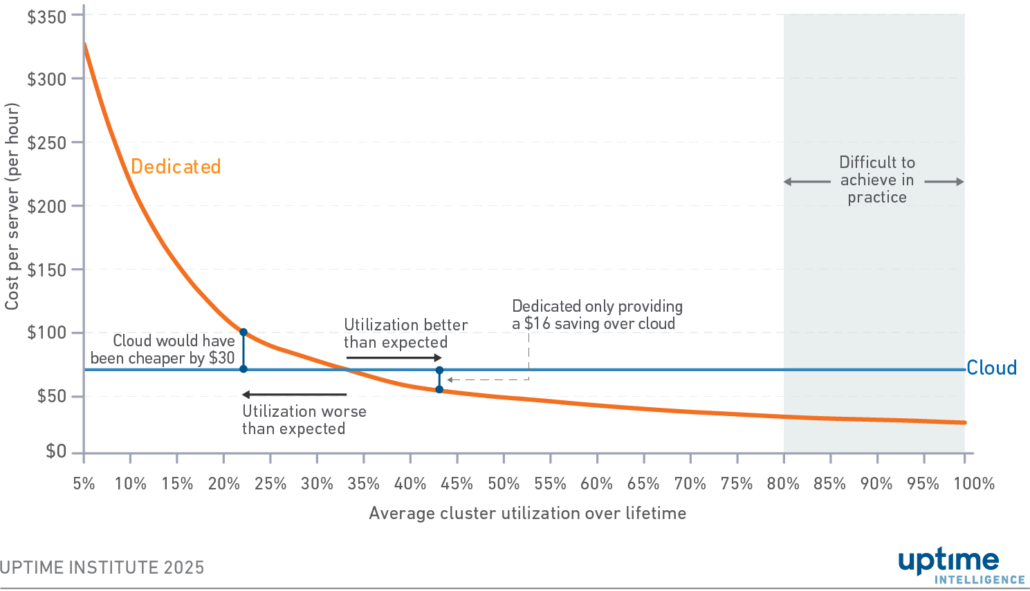
This risk of underutilizing an investment only exists with dedicated infrastructure. If an on-demand cloud resource is unused, it can be terminated at no cost. A cluster that has been purchased but is not being used is a sunk cost. In Figure 2, the dedicated infrastructure that fails to meet the threshold will continue to be more expensive than cloud until the utilization is increased. If cloud had been used, utilization would not be a consideration.
This risk is more pronounced because AI infrastructure is a brand new requirement for most enterprises. When cloud services were first launched, most organizations already had infrastructure, skills and procedures in place to manage their own data centers. As a result, there was no urgency to move to the cloud — in fact, migrating to the cloud required significant time and effort. Adoption was staggered.
Most organizations today, however, do not have existing AI infrastructure. Hype is triggering urgency and Chief Information Officers are under pressure to choose the best deployment method for AI requirements.
Using the model
The breakeven point will vary depending on an enterprise’s specific requirements. A discount on hardware list pricing or power can reduce the breakeven point, making dedicated infrastructure cheaper than the cloud, even if it is significantly underutilized.
Conversely, if a cloud buyer can reduce their costs through enterprise buying agreements or reserved instances, the breakeven point can move to the right, making the cloud cheaper than dedicated infrastructure. Cloud providers generally cut instance prices over time as demand shifts to newer instances equipped with the latest hardware.
While enterprise buyers need to conduct their own comparisons for their specific use case, the assumptions in this report provide a suitable benchmark.
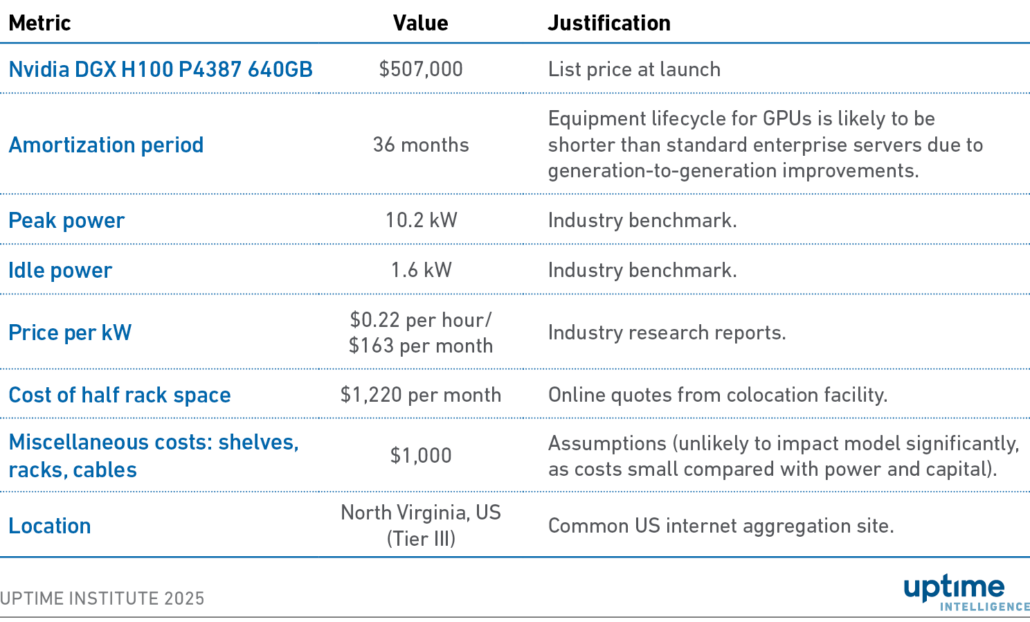
Table 3 shows a list of assumptions. Rather than estimating the costs of an enterprise data center, the cluster is assumed to be hosted in colocation facilities, primarily for reasons of simplicity. Colocation service pricing aggregates the cost of building the facility and data center labor, which are difficult to analyze from scratch.
Table 3 Comparison model assumptions
Conclusion
Companies considering purchasing an AI cluster must factor utilization at the heart of their calculations. What cluster capacity is needed, and how much will it be used for value-adding activity over its lifetime? The answers to these questions are not easy to determine, as they are affected by the roster of potential projects, the complexity of the models, the frequency of retraining and cluster upgrade cycles. The complexity is compounded by current hype, which makes predicting future demand and value challenging. Cloud presents a good place to start, as experimentation does not require capital investment. However, as AI requirements mature, dedicated equipment could make good financial sense, if used effectively.









