
AI power fluctuations strain both budgets and hardware
AI training at scale introduces power consumption patterns that can strain both server hardware and supporting power systems, shortening equipment lifespans and increasing the total cost of ownership (TCO) for operators.
These workloads can cause GPU power draw to spike briefly, even for only a few milliseconds, pushing them past their nominal thermal design power (TDP) or against their absolute power limits. Over time, this thermal stress can degrade GPUs and their onboard power delivery components.
Even when average power draw stays within hardware specifications, thermal stress can affect voltage regulators, solder joints and capacitors. This kind of wear is often difficult to detect and may only become apparent after a failure. As a result, hidden hardware degradation can ultimately affect TCO — especially in data centers that are not purpose-built for AI compute.
Strain on supporting infrastructure
AI training power swings can also push server power supply units (PSUs) and connectors beyond their design limits. PSUs may be forced to absorb rapid current fluctuations, straining their internal capacitors and increasing heat generation. In some cases, power swings can trip overcurrent protection circuits, causing unexpected reboots or shutdowns. Certain power connectors, such as the standard 12VHPWR cables used for GPUs, are also vulnerable. High contact resistance can cause localized heating, further compounding the wear and tear effects.
When AI workloads involve many GPUs operating in synchronization, power swing effects multiply. In some cases, simultaneous power spikes across multiple servers may exceed the rated capacity of row-level UPS modules — especially if they were sized following legacy capacity allocation practices. Under such conditions, AI compute clusters can sometimes reach 150% of their steady-state maximum power levels.
In extreme cases, load fluctuations of large AI clusters can exceed a UPS system’s capability to source and condition power, forcing it to use its stored energy. This happens when the UPS is overloaded and unable to meet demand using only its internal capacitance. Repeated substantial overloads will put stress on internal components as well as the energy storage subsystem. For batteries, particularly lead-acid cells, this can shorten their shelf life. In worst-case scenarios, these fluctuations may cause voltage sags or other power quality issues (see Electrical considerations with large AI compute).
Capacity planning challenges
Accounting for the effects of power swings from AI training workloads during the design phase is challenging. Many circuits and power systems are sized based on the average demand of a large and diverse population of IT loads, rather than their theoretical combined peak. In the case of large AI clusters, this approach can lead to a false sense of security in capacity planning.
When peak amplitudes are underestimated, branch circuits can overheat, breakers may trip, and long-term damage can occur to conductors and insulation — particularly in legacy environments that lack the headroom to adapt. Compounding this challenge, typical monitoring tools track GPU power every 100 milliseconds or more — too slow to detect the microsecond-speed spikes that can accelerate the wear on hardware through current inrush.
Estimating peak power behavior depends on several factors, including the AI model, training dataset, GPU architecture and workload synchronization. Two training runs on identical hardware can produce vastly different power profiles. This uncertainty significantly complicates capacity planning, leading to under-provisioned resources and increased operational risks.
Facility designs for large-scale AI infrastructure need to account for the impact of dynamic power swings. Operators of dedicated training clusters may overprovision UPS capacity, use rapid-response PSUs, or set absolute power and rate-of-change limits on GPU servers using software tools (e.g., Nvidia-SMI). While these approaches can help reduce the risk of power-related failures, they also increase capital and operational costs and can reduce efficiency under typical load conditions.
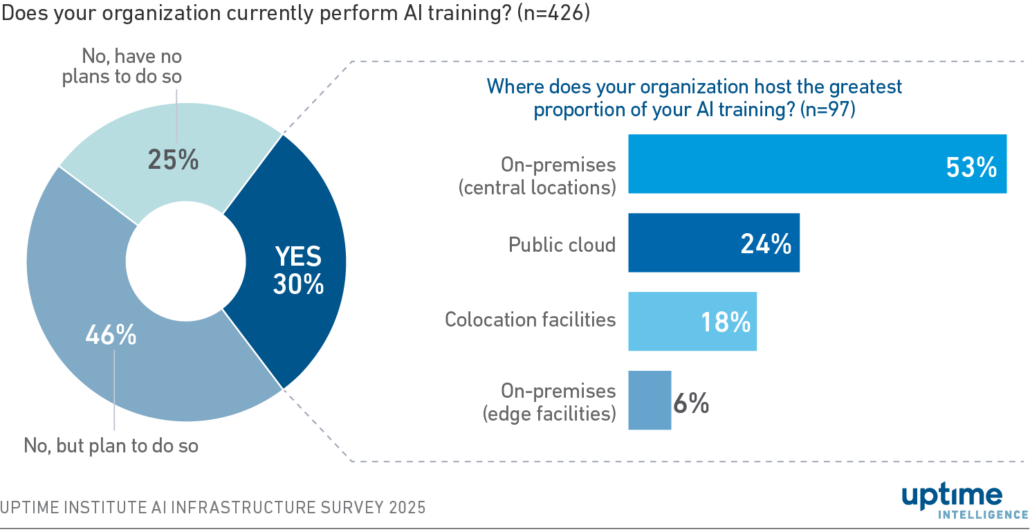
Many smaller operators — including colocation tenants and enterprises exploring AI — are likely testing or adopting AI training on general-purpose infrastructure. Nearly three in 10 operators already perform AI training, and of those that do not, nearly half expect to begin in the near future, according to results from the Uptime Institute AI Infrastructure Survey 2025 (see Figure 1).
Figure 1 Three in 10 operators currently perform AI training
Many smaller data center environments may lack workload diversity (non-AI loads) to absorb power swings or the specialized engineering to manage dynamic power consumption behavior. As a result, these operators face a greater risk of failure events, hardware damage, shortened component lifespans and reduced UPS reliability — all of which contribute to higher TCO.
Several low-cost strategies can help mitigate risk. These include oversizing branch circuits — ideally dedicating them to GPU servers — distributing GPUs across racks and data halls to prevent localized hotspots, and setting power caps on GPUs to trade some peak performance for longer hardware lifespan.
For operators considering or already experimenting with AI training, TDP alone is an insufficient design benchmark for capacity planning. Infrastructure needs to account for rapid power transients, workload-specific consumption patterns, and the complex interplay between IT hardware and facility power systems. This is particularly crucial when using shared or legacy systems, where the cost of misjudging these dynamics can quickly outweigh the perceived benefits of performing AI training in-house.
The Uptime Intelligence View
For data centers not specifically designed to support AI training workloads, GPU power swings can quietly accelerate hardware degradation and increase costs. Peak power consumption of these workloads is often difficult to predict, and signs of component wear may remain hidden until failures occur. Larger operators with dedicated AI infrastructure are more likely to address these power dynamics during the design phase, while smaller operators — or those using general-purpose infrastructure — may have fewer options.
To mitigate risk, these operators can consider overprovisioning rack-level UPS capacity for GPU servers, oversizing branch circuits (and dedicating them to GPU loads where possible), distributing heat from GPU servers across racks and rooms to avoid localized hotspots, and applying software-based power caps. Data center operators should also factor in more frequent hardware replacements during financial planning to more accurately reflect the actual cost of running AI training workloads.
The following Uptime Institute experts were consulted for this report:
Chris Brown, Chief Technical Officer, Uptime Institute
Daniel Bizo, Senior Research Director, Uptime Institute Intelligence
Max Smolaks, Research Analyst, Uptime Institute Intelligence
Other related reports published by Uptime Institute include:
Electrical considerations with large AI compute


 Getty
Getty





