
The weakest link dictates cloud outage compensation
Cloud providers offer services that are assembled by users into applications. An outage of any single cloud service can render an application unavailable. Importantly, cloud providers guarantee the availability of individual services, not of entire applications. Even if a whole application becomes unresponsive due to a provider outage, compensation is only due for the individual services that failed.
A small outage on a tiny part of an application may wreak havoc with an application (and even an entire business), but the provider will only award compensation for the weakest link that caused the outage.
A service level agreement (SLA) sets out the likely or promised availability of a specific cloud service, plus compensation due to the user if the provider fails to meet this availability. There is a different SLA for each cloud service.
Consider the cloud architecture in Figure 1, which shows traffic flows between virtual machines and a virtual load balancer. The load balancer distributes traffic across nine virtual machines. The virtual machines use the infrastructure as a service (IaaS) model, meaning the user is responsible for architecting virtual machines to be resilient. The load balancer, however, is a platform as a service (PaaS), which should mean the provider has architected it for resiliency. (More information on cloud models can be found in Uptime Institute’s recent report Cloud scalability and resiliency from first principles.)
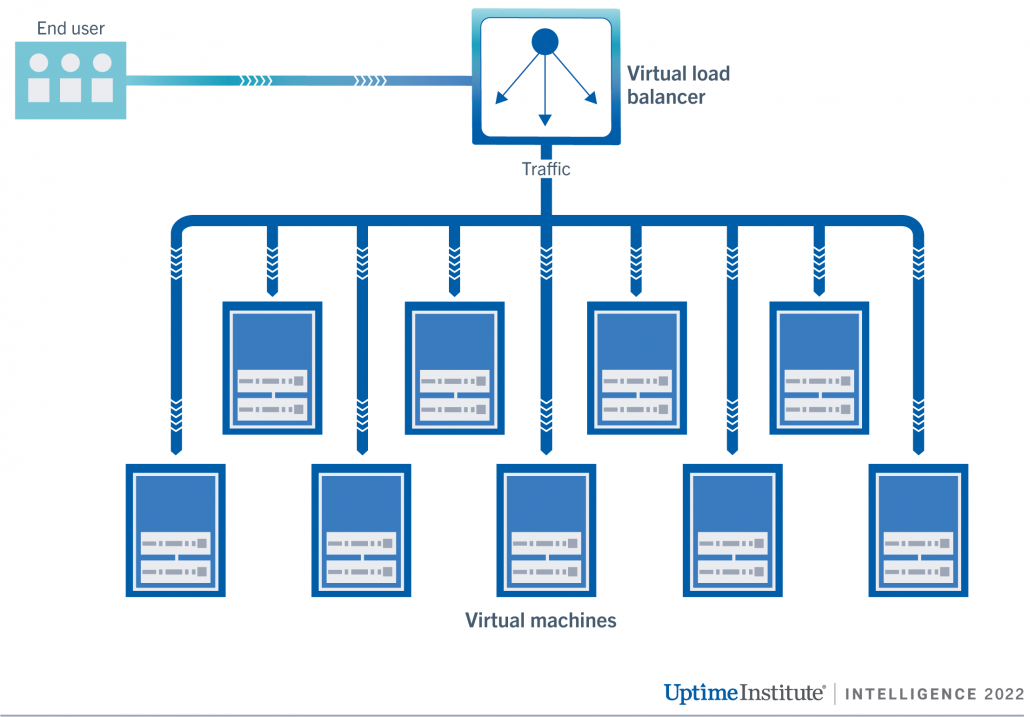
If the load balancer becomes unresponsive, the entire application is unusable as traffic can’t be routed to the virtual machines. The load balancer in this architecture is the weakest link.
The provider is responsible for the resiliency of the load balancer. Is the load balancer a single point of failure? It depends on the perception of the user. It may not be regarded as a single point of failure if the user is fully confident the provider has architected resiliency correctly through, for example, redundant servers or automatic failover. If the user is less convinced, they may consider the load balancer as a single point of failure because it is controlled by a single entity over which the user has limited visibility and control.
The virtual machines are still “available” because they are still in operation and can be accessed by the user for administration or maintenance — they just can’t be accessed by the end user via the application. The load balancer is the problem, not the virtual machines. In this scenario, no compensation is payable for the virtual machines even though the application has gone down.
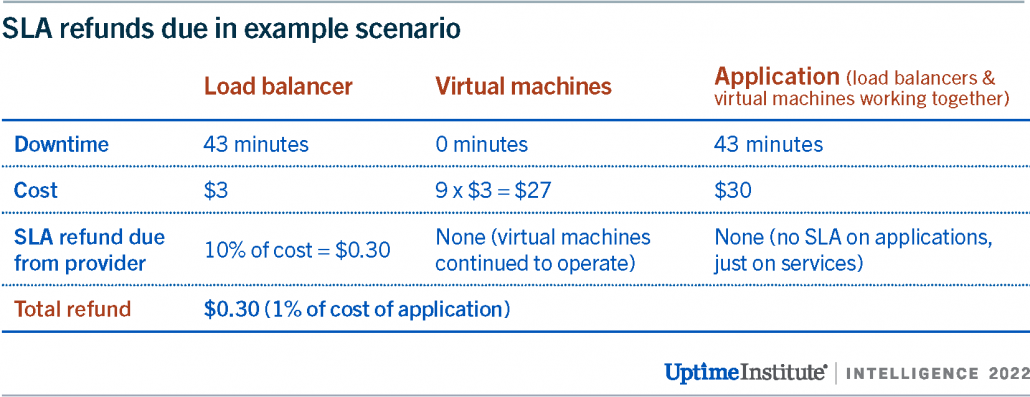
To understand the financial impact, we’ll assume each virtual machine and load balancer costs $3 per month. As an example of a cloud SLA, Microsoft Azure offers compensation of 10% of the monthly cost of the load balancer if it fails to be available for 99.99% to 99.9% of a month. Similar terms also apply to virtual machines.
If the load balancer is down for 43 minutes, then Microsoft Azure is obliged to pay 10% of the monthly fee of the load balancer, so $0.30 in this case. It is not obliged to pay for the virtual machines as these continued in operation, despite the application becoming unresponsive. The total monthly cost of the application is $30, and the compensation is $0.30, which means the payment for the outage is 1% of the monthly fee paid to Microsoft Azure — a paltry sum compared with the likely impact of the outage. Table 1 provides an overview of the refunds due in this scenario.
This example demonstrates two points. First, cloud providers provide services that users use to build applications. Their responsibility ends with these services. The analogy of cloud services as toy bricks may seem trite, but it conveys effectively some fundamental aspects of the cloud model. A toy company may guarantee the quality of its bricks, but it would not guarantee the quality of a model completed by an enthusiastic builder, no matter how well built.
In the architecture in Figure 1, for example, the user could have designed a more scalable application. They could have reduced the cost of virtual machines by implementing autoscaling, which would automatically terminate the unutilized virtual machines when not in use (such as when the load balancer went down). The user is ultimately responsible for building a resilient and scalable application, just as the quality of the toy model is the builder’s responsibility.
Second, this example also demonstrates that an SLA is not an insurance policy. It does not mitigate the business impact of downtime. In practice, compensation for cloud outages is likely to be less than originally assumed by users due to nuances in contract terms, which reduce the provider’s liability. Cloud customers must identify single points of failure in their applications and assess the risk and impact of an outage of these services. An outage of these services can render an application unavailable, but SLA compensation is unlikely to even cover the cost of the cloud services, let alone business losses. Ultimately, users are responsible for architecting greater resiliency in their applications to reduce the impact of outages.







 UI 2021
UI 2021
