
Implementing Data Center Cooling Best Practices
Step-by-step guide to data center cooling best practices will help data center managers take greater advantage of the energy savings opportunities available while providing improved cooling of IT systems
The nature of data center temperature management underwent a dramatic evolution when American Society of Heating, Refrigeration, and Air-conditioning Engineers (ASHRAE) adopted new operating temperature guidelines. A range of higher intake temperatures at the IT devices has enabled substantial increases in computer room temperatures and the ability to cool using a range of ‘free cooling’ options. However, recent Uptime Institute research has demonstrated that the practices used in computer rooms to manage basic airflow and the actual adoption of increased temperatures have not kept pace with the early adopters or even the established best practices. This gap means that many site operations teams are not only missing an opportunity to reduce energy consumption but also to demonstrate to executive management that the site operations team is keeping up with the industry’s best practices.
The purpose of this technical paper is to raise awareness of the relatively simple steps that can be implemented to reduce the cost of cooling a computer room. The engineering underlying these simple steps was contained in two Uptime Institute papers. The first, Reducing Bypass Airflow is Essential for Eliminating Computer Room Hotspots, published in 2004, contained substantial research demonstrating the poor practices common in the industry. In a nutshell, the cooling capacity of the units found operating in a large sample of data centers was 2.6 times what was required to meet the IT requirement, well beyond any reasonable level of redundant capacity. In addition, an average of only 40% of the cooling air supplied to the data centers studies was used for cooling IT equipment. The remaining 60% was effectively wasted capacity, required because of mismanagement of the airflow and cooling capacity.
Uptime Institute’s subsequent paper, How to Meet ‘24 by Forever’ Cooling Demands of Your Data Center was published in 2005. This paper contained 27 recommendations that were offered to remedy air management and over capacity conditions.
New research by Upsite Technologies®, which also sponsored research leading to the Uptime Institute’s 2004 publication on bypass airflow, found that the average ratio of operating nameplate cooling capacity in use in a newer, separate and significantly larger sample had increased from 2.6 to 3.9 times the IT requirement. Clearly, the data are still relevant and, disturbingly, this trend is going the wrong direction.
The 2013 Uptime Institute user survey (see p. 108), consisting of 1,000 respondents, found some interesting and conflicting responses. Between 50 and 71% (this varied by geography) reported that it was ‘very important’ to reduce data center energy consumption. Yet, 80% (up from 71% in 2012) indicated the electrical costs are paid by real estate, and therefore, generally not readily available to the IT decision makers when specifying equipment. Most strikingly, 43% (unchanged from 2012) use cooling air below 70°F/21°C, and 3% more (down from 6% in 2012) did not know what the temperatures were. More than half (57%) were using overall room air or return air temperatures to control cooling. These are the two least effective control points.
There is fundamental conflict between the desire to reduce operational expense (OPEX) and the lack of implementation of higher cooling temperatures and the resulting benefits. The goal of this paper is to give data center managers the tools to reduce the mechanical cooling power consumption through more efficient use of cooling units. Improving airflow management will allow for elevated return air temperatures and a larger ΔT across the cooling unit resulting in increased capacity of the cooling unit. This allows for the cooling to be performed by fewer cooling units to reduce mechanical energy consumption. Further cooling system best practices are discussed, including transition to supply air control, increasing chilled water temperatures, and refurbishment or replacement of fixed speed cooling units with variable speed capability.
Uptime Institute has consistently found that many site managers are waiting for the ‘next big breakthrough’ before springing into action. The dramatic OPEX, subsequent environmental and cooling stability benefits of improved cooling air management, increased operating temperatures, variable speed cooling fans and other best practices are not being exploited by the data center industry at large.
In some cases, managers are overwhelmed by engineering speak and lack a straightforward guideline. This technical paper is designed to assist site managers with a simple high-level guide to implement these best practices quickly and successfully, and includes some straightforward metrics to get the attention of the leadership team. One such metric is the ratio of operating cooling capacity in the computer room vs. the cooling load in the computer room, which is a simple, but effective, way to identify stranded capacity and unnecessary operation of cooling units.
This paper lists 29 steps intended to focus effort on reducing the cost of cooling. Select actions may require the involvement of consultants, engineers or vendors. The first 17 steps have been divided into two groups, one called Preparatory Metrics and the other Initial Action to Manage Airflow.
Taking these steps will establish a baseline to measure the program’s effectiveness and to ensure proper airflow management. Three sets of subsequent actions describe will describe 12 steps for reducing the number of cooling units, raising temperatures in the computer room and measuring the effectiveness of these actions. The third set of actions will also set the stage driving continuous improvement in the facility.
Reductions in the cost of cooling can be achieved without any capital investment: none of the 29 actions in this paper require capital! Additional energy-efficient actions are also described but will require a more comprehensive approach, often involving engineering design and potentially capital investment. Other benefits will be realized when the cost of cooling is reduced. Correcting air management reduces hot spots, and taking cooling units off line can reduce maintenance costs.
Preparatory Metrics.
This first group of steps captures the basic data collection necessary to capture the operating status of the computer room for later comparison. It is essential that this be the first group of steps as these metrics will provide the basis for reporting later success in reducing energy consumption and reducing or eliminating hot spots. Develop the work plan covering the proposed changes.
Initial Action to Manage Airflow.
The second group of steps guides step-by-step actions to rearrange existing perforated tiles and close bypass airflow openings such as cable holes and the face of the rack. Proper air management is necessary before changing the temperature in the computer room.
- Subsequent Action One. Reducing the number of operating cooling units. The number of cooling units running should be adjusted to represent the necessary capacity plus the desired level of redundancy. This will involve turning selected units off.
- Subsequent Action Two. Raising the temperature. Over time, increase the temperature of the air being supplied to the IT device intakes. A very slow and conservative approach is presented.
- Subsequent Action Three. Reviewing and reporting metrics. Regular measurement and reporting allows the data center integrated operations team of both IT and Facilities professionals to make informed data center management decisions and will drive continuous improvement within the organization.
Selectively, some groups of steps can be done on a common initiative depending on how a particular project is being implemented. The approach in this paper is intentionally conservative.
Limitations and Conditions
Implementing change in any critical environment must be done carefully. It is important to develop and coordinate with IT a detailed site plan to supplement the 29 steps from this technical paper; this is a critical requirement for any site concerned with availability, stability and continuity of service. Retain appropriate consultants, engineers or contractors as necessary to completely understand proposed changes, especially with the physical cooling equipment changes outlined in Additional Advanced Energy Efficient Actions.
Because of air-cooling density limitations, higher density equipment may need to be supplemented with localized cooling solutions, direct liquid cooling or other innovations such as extraction hoods or chimneys. Traditionally, the cap for all ‘air cooling ’ was a power density of 7 kilowatts (kw) per rack, and that was only possible when all established best practices were being followed. Failure to follow best practices can lead to problems cooling even two kilowatt racks.
Experience shows that consistent and complete adoption of the steps in this technical paper enables successful cooling of server racks and other IT equipment at higher densities. Sites that excel at the adoption of these practices, sometimes coupled with commonly available technologies, can successfully air cool racks exceeding 10 kW (see Case Study 2). Other contemporary examples have successfully applied air cooling to even higher densities.
For sites with rack densities greater than 6 kW per rack, the Uptime Institute recommends Continuous Cooling. Continuous Cooling is where the computer room heat removal is uninterrupted during the transition from utility power to engine generator power. This is the direct analogy to uninterrupted power to the IT equipment. This recommendation is based on multiple recorded temperature excursions in the industry where the temperature and the rate of change of the temperature both exceed ASHRAE guidelines. In one case, a computer room with 250 racks at 6 kW went from 72°F to 90+°F (22°C to 32+°C) in 75 seconds when the cooling was lost.
Increasing the operating temperature of a computer room may shorten the ridethrough time for a momentary loss of cooling. Real-event experience, however, suggests the change in the ride-through time will be seconds, not minutes or hours. This explanation, which is often cited for not raising the operating temperature, is not based on fact.
ASHRAE Temperature Guidelines
Current ASHRAE TC 9.9 publications can be obtained at http://tc99.ashraetcs.org/documents.html. The TC9.9 publications should be fully understood before selecting a higher operating temperature. The ability of legacy or heritage equipment to operate in the newer temperature ranges should be validated by the IT team.
Cold Aisle/Hot Aisle
The physical arrangement of the IT equipment into what is known as Cold Aisle/Hot Aisle is another best practice. This configuration places the intake of IT equipment on the Cold (supply) Aisle and the discharge of warmer air toward the Hot (return) Aisle. Current practices permit most computer rooms to use 75°F/24°C supply in the Cold Aisle, understanding that the only temperature that matters in a computer room is the air at the intake to the computer hardware. The Hot Aisle will be substantially warmer. Noticing dramatically different temperatures while walking through a computer room with Cold Aisles/Hot Aisles is a demonstration of successful implementation and operating practices.
Proper adoption of Cold Aisle/Hot Aisle methodology improves the stability and predictability of cooling and is a key step to minimizing the mixing of hot and cold air. However, an existing legacy computer room that does not utilize a Cold Aisle/Hot Aisle configuration can still benefit from improved airflow management. Perforated floor tiles providing raised-floor cooling air should be placed immediately adjacent to the front of the rack they are cooling. Temperatures in a legacy environment will not be as distinctive as in a Cold Aisle/Hot Aisle environment, and extra caution is required when implementing these best practices. Additional check points should be added to ensure that undesired temperature increases are identified and quickly addressed during the rearrangement of floor tiles.
For maximum benefit, a strategic computer room master plan should be developed. This master plan will identify the arrangement of the rows of IT equipment, the positions in rows or the room for power support equipment, and the number and arrangement of the cooling units to support the ultimate capacity of the space. The master plan also reserves locations for IT, power and cooling equipment that may not be installed for some time, so that when the equipment is required, there is not a crisis to determine where to install it; it is preplanned. A computer room master plan is of value for a new room or reconfiguring an existing room.
29 Cooling Best Practices
Group one: Preparatory metrics
1. Determine the IT load in kilowatts.
2. Measure the intake temperature across the data center, including where hot spots have been experienced. At a minimum, record the temperature at mid-height at the end of each row of racks and at the top of a rack in the center of each row. Record locations, temperatures and time/date manually or using an automated system. These data will be used later as a point of comparison.
3. Measure the power draw to operate the cooling units in kilowatts. Often, there is a dedicated panel serving these devices. This may be accessible from a monitoring system. These data will be used later as a point of comparison and calculation of kilowatt-hours and long-term cost savings.
4. Measure the room’s sensible cooling load as found. This can be done by measuring the airflow volume for each cooling unit and recording the supply and return temperatures for each unit that is running. The sensible capacity of each operating unit in kW for each unit can be calculated using the expression Q sensible (kW) = 0.316*CFM*(Return Temp°F – Supply Temp°F)/1000 [Q sensible (kW) = 1.21*CMH*(Return Temp°C – Supply Temp°C)/3600]
The room’s sensible load is the sum of each cooling unit running in the room. Organize the data in a spreadsheet or similar tool to record each data point, supply and return temperature, ΔT (return-supply), airflow, kilowatt sensible and sum to provide overall room sensible load. Confirm that entire IT load is being serviced by the cooling system, that there is not additional IT load in another room and that the cooling plant is not supporting any non-IT load.
Compare the cooling load to the IT load for a point of reference.
5. Using the airflow and return air temperature measured in the previous step, request the sensible capacity of each unit in kilowatts from the equipment vendor. Enter this nominal sensible capacity in the spreadsheet. Sum the sensible capacity for the units that are operating. This is a quick and easy approximation of the sensible-cooling capacity of the cooling units in use. More complex methods are available but were not included here for simplicity.
6. Divide the overall room operating cooling sensible capacity in kilowatts determined in previous step by the sensible operating cooling load determined in Step 4. This number presents a simple ratio of operating capacity versus cooling load. The ratio could be as low as 1.15 (where the cooling capacity matches IT load with one cooling unit in six redundant), but will likely be much higher. This ratio is a benchmark to evaluate subsequent improvement as reduction of this ratio will occur with the reduction of operating cooling units.
7. Cooperatively with IT, determine the maximum allowable intake temperature for the new operating environment. For temperatures above 75°F, there may be offsetting power increases within the IT devices from their onboard cooling fans.
8. Using the data developed above, create a work plan outlining goals of the effort, detail the metrics that will be monitored to ensure the cooling environment is not disrupted, specify a back-out plan should a problem be discovered and identify the performance metrics that will be tracked for rack inlet temperatures, power consumption, etc. This plan should be fully communicated with IT as a key member of the critical operations team.
Group two: Initial action to manage airflow
9. Relocate all raised-floor perforated tiles to the Cold Aisle. Replace perforated tile supporting a given rack should be placed immediately in front of the rack. As a starting baseline, each rack with IT equipment producing cooling load should have a single perforated floor tile in front of it. Empty racks and racks with no electrical load should have a solid tile in front of them. Give special consideration to racks populated with network equipment like switches or patch panels.
10. If a return air plenum is used, ensure that the placement of ceiling return grilles aligns with the Hot Aisles.
11. Seal the vertical front of the racks using blanking plates or other systems to prevent Cold Aisle air from moving through the empty rack positions into the Hot Aisle.
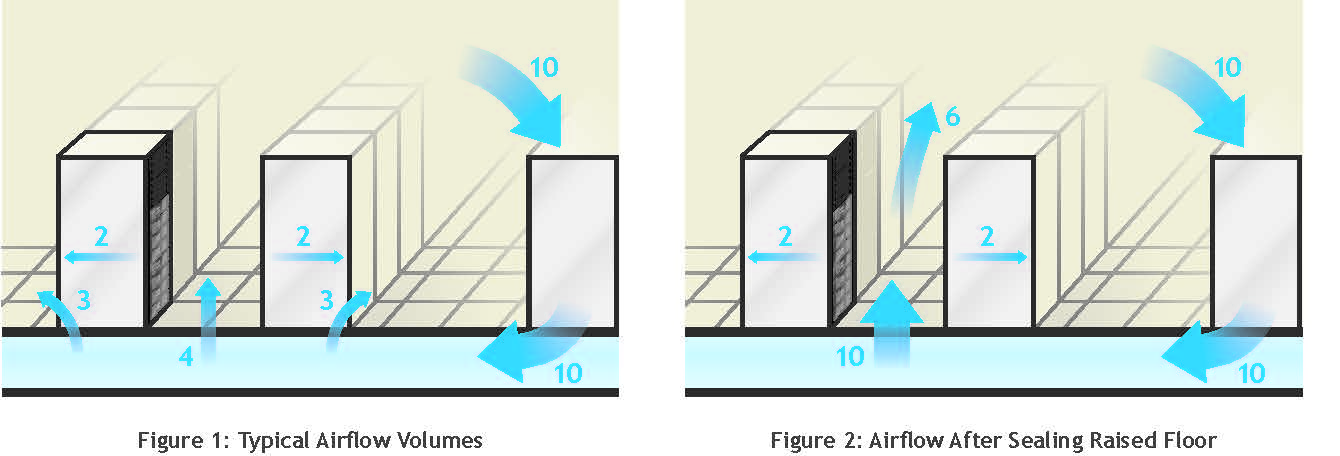
12. Seal the cable holes in raised floor, if used.
13. Seal any holes in the walls or structure surrounding the computer room. Check walls below the raised floor and above the ceiling. Check for unsealed openings in the structure under or over the computer room. Typical issues are found where conduits, cables or pipes enter the computer room.
14. Seal any supply air leakage around the cooling units, if they are located in the computer room.
15. Ensure that all cooling units in the space are equipped with a backflow damper or fabricate covers for units designated as off to prevent backflow of cooling through powered-off cooling units.
16. Seal any leakage of cooling air at power distribution units, distribution panels or other electrical devices mounted on the raised floor.
17. Record the temperatures at the same locations as in Step 2. Compare this and prior readings to determine if any intake temperatures have increased. If an increase is observed, increase airflow to the problem rack by moving a raised-floor perforated tile from an area that does not have any hot spots or by replacing the standard perforated floor tile with a higher flow rate perforated floor tile.
Subsequent action one: Reducing the number of operating cooling units by shutting units off.
18. Identify the cooling units with the lowest sensible load. These units will be the first units to be turned off as the following process is implemented.
19. Estimate the number of required cooling units by dividing the IT load by the smallest sensible cooling unit capacity. This will approximate the number of cooling units needed to support the IT load.
20. Uptime Institute recommends redundancy in large computer rooms of 1 redundant unit for every six cooling units. Smaller or oddly shaped rooms may require a higher level of redundancy. Divide the required number of cooling units by six to determine the number of redundant cooling units. Round up to the next higher whole number. This is the suggested number of redundant cooling units for the IT load.
21. Add the results of the two previous steps. This will be the desired number of cooling units necessary to operate to meet the IT load and provide 1:6 redundant cooling units. This should be fewer than the total number of cooling units installed.
22. Turn off one operating cooling unit each week until only the desired number of cooling units determined in the previous step remains operating.
23. With each ‘excess’ cooling unit being shut off, examine reducing the number of perforated tiles to match the reduced airflow being supplied to the room. If a temperature increase is observed, increase airflow to the problem rack by adding perforated floor tiles or utilizing higher flow rate perforated floor tiles. The placement of floor tiles to appropriately match cooling supply is an iterative process.
24. Before each subsequent reduction in the number of operating cooling units, record the temperatures at the same locations as in Step 2. Compare this and prior readings to determine if any server intake temperatures have increased. If an increase is observed, increase airflow to the problem rack by moving a perforated tile from an area that does not have any hot spots.
25. When the desired number of units has been reached, record the power draw for the cooling units as in Step 3. This may be possible through existing monitoring. Compare the before and after to observe the reduction in power draw.
Subsequent action two: Raising the temperature in the computer room.
26. Increase the temperature set point on each cooling unit one or two degrees a week until the server intake air is at the desired level, for example the highest server intake temperature is 75°F/24°C. To accomplish this faster, a greater rate of change should be discussed with and agreed to by the data center integrated operations team. (Note: this step can be completed regardless of whether the cooling unit uses supply or return air control. If the unit has return air control, the set point will seem quite high, but the supply air will be in the acceptable range.)
27. Before each subsequent increase in set point temperature, record the temperatures at the same locations as in Step 2. Compare this and prior readings to determine if any server intake temperatures have increased. If an increase is observed, increase airflow to the problem rack by moving a perforated tile from an area that does not have any hot spots.
Subsequent action three: Review and report metrics.
28. Re-create the preparatory metrics from Steps 1-6 and compare to the original values. This includes the following metrics:
- Total cooling unit power consumption
- Ratio of operating cooling capacity and cooling load
- IT device inlet temperatures
29. Calculate the overall power savings based on the implemented measures and estimate annual operations savings based upon kilowatt-hours reduced and the average cost of power. Report the progress to the integrated data center operations team.
Additional Advanced Energy-Efficient Actions
There are additional measures, which can be taken in order to further increase the overall efficiency of the cooling systems supporting the data center, including implementing variable speed/frequency fan drives, utilizing supply air control and increasing the chilled-water temperature where chilled-water systems are utilized. These measures, while requiring increased engineering study and operational awareness prior to implementation, can continue to lower the amount of electricity required for the cooling plant, while simultaneously maintaining a more consistent ambient environment in the data center.
Implementing supply air control
Supply air control typically requires the addition of supply air temperature sensors, as legacy air conditioners are typically not equipped with these devices. The supply air sensors will be the modulation control point for the units to ensure a consistent supply air temperature for the data center.
Most legacy data centers are still utilizing standard return air control methodologies. However, data centers with supply air control methods are realizing two important benefits. First, in conjunction with good airflow management practices, supply air control guarantees a consistent inlet air temperature through all cold aisles in the data center. Second, it reduces the importance of the ΔT of the air handlers. Data centers utilizing return air control are forced to use an artificially low return air set point in order to guarantee that the cold aisle temperatures do not exceed their normal design temperature. But, this is not an issue for data centers utilizing supply air control.
Considerations
Supply air control typically reacts much faster than return air control, so there is the possibility of increased ‘hunting ’ to find the set point. Often, implementing supply air control requires modification of the control algorithms that the units use to modulate cooling. This should be done in close concert with the original equipment manufacturer (OEM).
This control scheme should use an adjustable set point for supply air, and additionally there should not be any automatic reset on the desired supply air temperature. The objective is to have all underfloor air at the same temperature.

Figure 2. The power consumption of a fan is a function of the cube of the fan speed.
Implementing variable speed fan drives
Since the power consumption of a fan is a function of the cube of the fan speed, operating additional variable speed cooling units or fans will further reduce power consumption (see Figure 2). This can be accomplished by retrofitting any constant speed cooling fans to variable speed or by replacing legacy units with new units with built in variable speed capability. Implementing variable speed fan drives will require close interaction with the OEM of the cooling units, and possibly, other assistance, depending on the qualifications of the facility staff.
Considerations
There are various ways of controlling the variable speed fans of the cooling units, but the most common is the use of underfloor static pressure. A less consistently applied control method is controlling variable speed fans based on temperature sensors within the cold aisle. Static pressure can be difficult to measure accurately.
Therefore, it is a good practice to have groups or even all units operating at the same speed. This helps to ensure that units are not constantly fighting each other and excessively modulating to maintain the set point.
As a best practice, the implementation of variable speed fan drives should not be done without prior installation of supply air control on the cooling units. Using variable speed fan drives in conjunction with return air control can lead to lower temperature differentials (ΔT’s), which can in turn lead to increased Cold Aisle temperatures, potentially even above the desired limit. To alleviate this issue, the return air set point has to be reduced, thereby defeating the potential savings realized by implementing the variable speed fan drives.
Using variable speed fan drives will typically change the airflow characteristics of the room. Therefore, it is important to monitor temperatures at the inlet of the IT devices. If higher temperatures are observed, perforated floor tile type and location may need modification.
Increasing Chilled Water Temperature
A chilled water system is one of the largest single facility power consumers in the data center. Raising the air handler temperature set point provides the opportunity to increase the temperature of the chilled water and further reduce energy consumption. Typical legacy data centers have chilled water set points between 42-45°F (6-7°C). Facilities that have gone through optimization of their cooling systems have successfully raised their chilled water temperatures to 50°F (10°C) or higher.
Considerations
The maximum allowable chilled water temperature will be based on the performance capabilities of both the chiller and the air handler units. Therefore, it is imperative to work in close contact with both the chiller and air handler unit OEMs to ensure that the chilled water temperature can be increased without impacting the data center. Increasing the chilled water temperature will have an impact on the capacity of the cooling units and should be implemented very slowly, potentially only increasing the set point by a single degree per week.
Some facilities require colder chilled water temperature in order to dehumidify the air in the data center. An engineering analysis should be performed to determine whether or not a low chilled water temperature is required for dehumidification processes. The savings from implementing higher chilled water temperatures can be so great that investigating alternative dehumidification methods may be warranted.
Case Study 1: How NOT to implement changes in a computer room.
A mechanical system diagnostic assessment was performed for a confidential client’s global support data center’s 40,000-ft2 (3,700-m2) computer room with over 70 chilled-water cooling units. Only 35 units (including redundancy) were required to keep the room cool. Upon receiving the preliminary study, the facility staff began turning cooling units off in a random and unplanned manner and without communicating with IT. Within five minutes, critical computer and storage equipment had shut down, interrupting the mission-critical computing (internal protective sensors that had sensed high temperatures automatically shut down some of the hardware). IT management, which was not aware of the initiative to reduce energy use, immediately demanded all cooling units be turned back on and the hot spots went away. After this very unpleasant experience, no further attempts were made at cooling optimization.
The failed attempt to reduce facility energy consumption outlined in this case study illustrates the necessity of making changes in a computer environment in a methodical, planned and well communicated way. Purposefully implementing the best practices established by Uptime Institute research can be done with great success if done in a prudent manner with the involvement and support of IT management.
Case Study 2: Overcoming legacy capabilities in a 20-year-old data center.
Designed for less than 2 kW per rack, Agriculture and Agri-Food Canada (AAFC)’s 20-year old data center was updated to successfully support multiple 10-kW racks using only air cooling. Best practices were followed for managing airflow, including selective use of hot-air containment and extraction technology. The temperatures in the room stabilized and previous hot spots were eliminated, in addition to supporting racks of a dramatically higher density than previously envisioned. This project earned AAFC and Opengate a 2011 GEIT award winner in the Outstanding Facilities Product in a User Deployment category. In addition, Opengate made the project the subject of a 2012 Symposium Technology Innovation presentation.
Case Study 3: A 40-year-old data center updates fan monitoring and controls to reduce fan energy consumption by 24%.
Lawrence Berkeley National Laboratories (a 2013 GEIT Finalist) used variable- speed controls to slow fan speeds. Since fan energy consumption is a function of the cube of fan speed, slowing down the fans brings an immediate and measurable reduction in energy consumption. This implementation used available technology and was performed after best practices in air management were met.
About the Authors
 W. Pitt Turner IV, PE, is the executive director emeritus of Uptime Institute, LLC. Since 1993 he has been a senior consultant and principal for
W. Pitt Turner IV, PE, is the executive director emeritus of Uptime Institute, LLC. Since 1993 he has been a senior consultant and principal for
Uptime Institute Professional Services (UIPS), previously known as ComputerSite Engineering, Inc. Uptime Institute includes UIPS, the Institute Uptime Network, a peer group of over 100 data center owners and operators in North America, EMEA, Latin America, and Asia Pacific, as well as the Uptime Institute Symposium, a major annual international conference. Uptime Institute is an independent operating unit of The 451 Group.
Before joining Uptime Institute, Mr.Turner was with Pacific Bell, now AT&T, for more than 20 years in their corporate real estate group, where he held a wide variety of leadership positions in real estate property management, major construction projects, capital project justification and capital budget management. He has a BS Mechanical Engineering from UC Davis and an MBA with honors in Management from Golden Gate University in San Francisco. He is a registered professional engineer in several states. He travels extensively and is a school-trained chef.
 Keith Klesner’s career in critical facilities spans 14 years and includes responsibilities ranging from planning, engineering, design and construction to start-up and ongoing operation of data centers and mission-critical facilities. In the role of Uptime Institute vice president of Engineering, Mr. Klesner provides leadership and strategic direction to maintain the highest levels of availability for leading organizations around the world. Mr. Klesner performs strategic-level consulting engagements, Tier Certifications and industry outreach—in addition to instructing premiere professional accreditation courses. Prior to joining the Uptime Institute, Mr. Klesner was responsible for the planning, design, construction, operation and maintenance of critical facilities for the U.S. government worldwide. His early career includes six years as a U.S. Air Force officer. He has a Bachelor of Science degree in Civil Engineering from the University of Colorado- Boulder and a Masters in Business Administration from the University of LaVerne. He maintains status as a professional engineer (PE) in Colorado and is a LEED-accredited professional.
Keith Klesner’s career in critical facilities spans 14 years and includes responsibilities ranging from planning, engineering, design and construction to start-up and ongoing operation of data centers and mission-critical facilities. In the role of Uptime Institute vice president of Engineering, Mr. Klesner provides leadership and strategic direction to maintain the highest levels of availability for leading organizations around the world. Mr. Klesner performs strategic-level consulting engagements, Tier Certifications and industry outreach—in addition to instructing premiere professional accreditation courses. Prior to joining the Uptime Institute, Mr. Klesner was responsible for the planning, design, construction, operation and maintenance of critical facilities for the U.S. government worldwide. His early career includes six years as a U.S. Air Force officer. He has a Bachelor of Science degree in Civil Engineering from the University of Colorado- Boulder and a Masters in Business Administration from the University of LaVerne. He maintains status as a professional engineer (PE) in Colorado and is a LEED-accredited professional.
 Ryan Orr has been an Uptime Institute Professional Services Consultant since January 2012. In this role, he performs Tier Certifications of Design, Constructed Facility and Operational Sustainability. Additionally, he performs M&O Stamp of Approval reviews and custom consulting activities. Prior to joining the Uptime Institute, Mr. Orr was with the Boeing Company, where he provided engineering, maintenance and operations support to both legacy and new data centers nationwide. This support included project planning, design, commissioning and implementation of industry best practices for mechanical systems. Mr. Orr holds a BS degree in Mechanical Engineering from Oregon State University.
Ryan Orr has been an Uptime Institute Professional Services Consultant since January 2012. In this role, he performs Tier Certifications of Design, Constructed Facility and Operational Sustainability. Additionally, he performs M&O Stamp of Approval reviews and custom consulting activities. Prior to joining the Uptime Institute, Mr. Orr was with the Boeing Company, where he provided engineering, maintenance and operations support to both legacy and new data centers nationwide. This support included project planning, design, commissioning and implementation of industry best practices for mechanical systems. Mr. Orr holds a BS degree in Mechanical Engineering from Oregon State University.







