 2019
2019How to avoid outages: Try harder!
Uptime Institute has spent years analyzing the roots causes for data center and service outages, surveying thousands of IT professionals throughout the year on this topic. According to the data, the vast majority of data center failures are caused by human error. Some industry experts report numbers as high as 75%, but Uptime Institute generally reports about 70% based on the wealth of data we gather continuously. That assumption immediately raises an important question: Just how preventable are most outages?
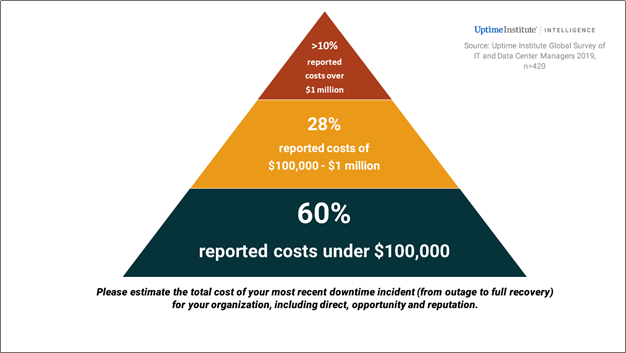
Certainly, the number of outages remains persistently high, and the associated costs of these outages are also high. Uptime Institute data from the past two years demonstrates that almost one-third of data center owners and operators experienced a downtime incident or severe degradation of service in the past year, and half in the previous three years. Many of these incidents had severe financial consequences, with 10% of the 2019 respondents reporting that their most recent incident cost more than $1 million.
These findings, and others related to the causes of outages, are perhaps not unexpected. But more surprisingly, in Uptime Institute’s April 2019 survey, 60% of respondents believed that their most recent significant downtime incident could have been prevented with better management/processes or configuration. For outages that cost greater than $1 million, this figure jumped to 74%, and then leveled out around 50% as the outage costs increased to more than $40 million. These numbers remain persistently high, given the existing knowledge available on the causes and sources of downtime incidents and the costs of many downtime incidents.
Data center owners and operators know that on-premises power failures continue to cause the most outages (33%), with network and connectivity issues close behind (31%). Additional failures attributed to colocation providers could also have been prevented by the provider.
These findings should be alarming to everyone in the digital infrastructure business. After years of building data centers, and adding complex layers of features and functionality, not to mention dynamic workload migration and orchestration, the industry’s report card on actual service delivery performance is less than stellar. And while these sorts of failures should be very rare in concurrently maintainable and fault tolerant facilities when appropriate and complete procedures are in place, what we are finding is the operational part of the story falls flat. Simply put, if humans worked harder to MANAGE the well-designed and constructed facilities better, we would have fewer outages..
Uptime Institute consultants have underscored the critically important role procedures play in data center operations. They remind listeners that having and maintaining appropriate and complete procedures is essential to achieving performance and service availability goals. These same procedures can also help data centers meet efficiency goals, even in conditions that exceed planned design days. Among other benefits, well conceived procedures and the extreme discipline to follow these procedures helps operators cope with strong storms, properly perform maintenance and upgrades, manage costs and, perhaps most relevant, restore operations quickly after an outage.
So why, then, does the industry continue to experience downtime incidents, given that the causes have been so well pinpointed, the costs are so well-known and the solution to reducing their frequency (better processes and procedures) is so obvious? We just don’t try hard enough.
When asking our constituents about the causes for their outages, there are perhaps as many explanations as there are respondents. Here are just a few questions to consider when looking internal at your own risks and processes:
- Does the complexity of your infrastructure, especially the distributed nature of it, increase the risk that simple errors will cascade into a service outage?
- Is your organization expanding critical IT capacity faster than it can attract and apply the resources to manage that infrastructure?
- Has your organization started to see any staffing and skills shortage, which may be starting to impair mission-critical operations?
- Do your concerns about cyber vulnerability and data security outweigh concerns about physical infrastructure?
- Does your organization shortchange training and education programs when budgeting?
- Does your organizations under-invest in IT operations, management, and other business management functions?
- Does your organization truly understand change management, especially when many of your workloads may already be shared across multiple servers, in multiple facilities or in entirely different types of IT environments including co-location and the cloud?
- Does you organization consider the needs at the application level when designing new facilities or cloud adoptions?
Perhaps there is simply a limit to what can be achieved in an industry that still relies heavily on people to perform many of the most basic and critical tasks and thus is subject to human error, which can never be completely eliminated. However, a quick survey of the issues suggests that management failure — not human error — is the main reason that outages persist. By under-investing in training, failing to enforce policies, allowing procedures to grow outdated, and underestimating the importance of qualified staff, management sets the stage for a cascade of circumstances that leads to downtime. If we try harder, we can make progress. If we leverage the investments in physical infrastructure by applying the right level of operational expertise and business management, outages will decline.
We just need to try harder.
More information on this and similar topics is available to members of the Uptime Institute which can be initiated here.






 UI 2020
UI 2020

