Fastly outage underscores slow creep of digital services risk
A recent outage at content delivery network Fastly took down thousands of websites in different countries, including big names, such as Amazon, Twitter and Spotify, for nearly an hour. It is the latest large outage highlighting the downside of a key trend in digital infrastructure: The growth in dependency on digital service providers can undermine infrastructure resilience and business continuity.
The conundrum here is one of conflicting double standards. While many companies expend substantial money and time on hardening and testing their own data center and IT infrastructure against disruptions, they also increasingly rely on cloud service providers whose architectural details and operational practices are largely hidden from them.
Some confusion stems from high expectations and a high level of trust in the resiliency of the greatly distributed topologies of cloud and network technologies — often amounting to a leap of faith. Large providers routinely quote five nines or more availability or imply that system-wide failure is nearly impossible — but this is clearly not the case. While many do deliver on these promises most of the time, outages still happen. When they do, the impact is often broad and wide.
Fastly is far from being a lone culprit. In our report Annual outage analysis 2021: The causes and impacts of data center outages, Uptime Institute counts over 80 major outages at cloud providers in the last five years (not including other digital services and telecommunication providers). The Fastly outage serves as a reminder that cloud- and network-based services are not invulnerable to service interruptions — in fact, they sometimes prove to be surprisingly fragile, susceptible to tiny errors.
Fastly’s own initial postmortem of the event notes that the global outage was a result of a legitimate and valid configuration change by a single customer. That change led to an unexpected effect on the wider system, ultimately taking down dozens of other customers’ services. Fastly said it did not know how the bug made it into production. In some ways, this Fastly outage is similar to an Amazon Web Services (AWS) incident a few years ago, when a single storage configuration error made by an administrator ground some AWS services to a near halt on the US East Coast, causing major disruption.
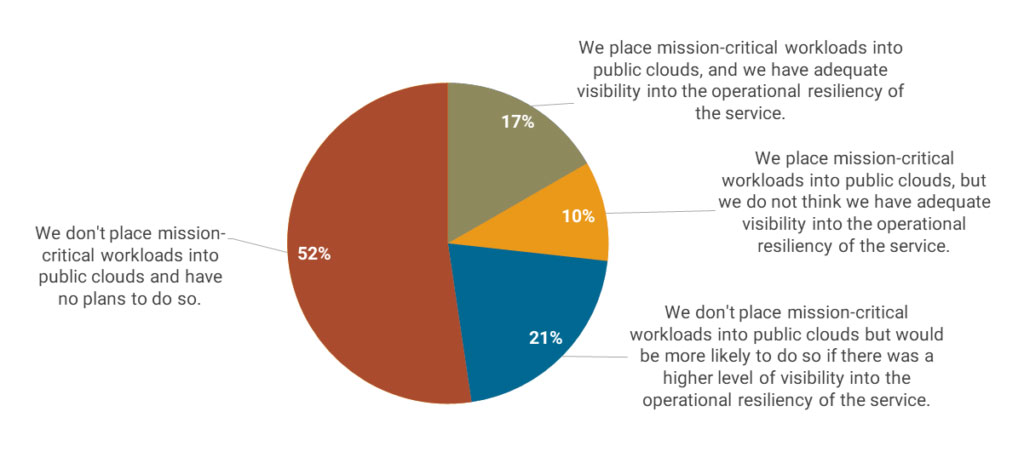
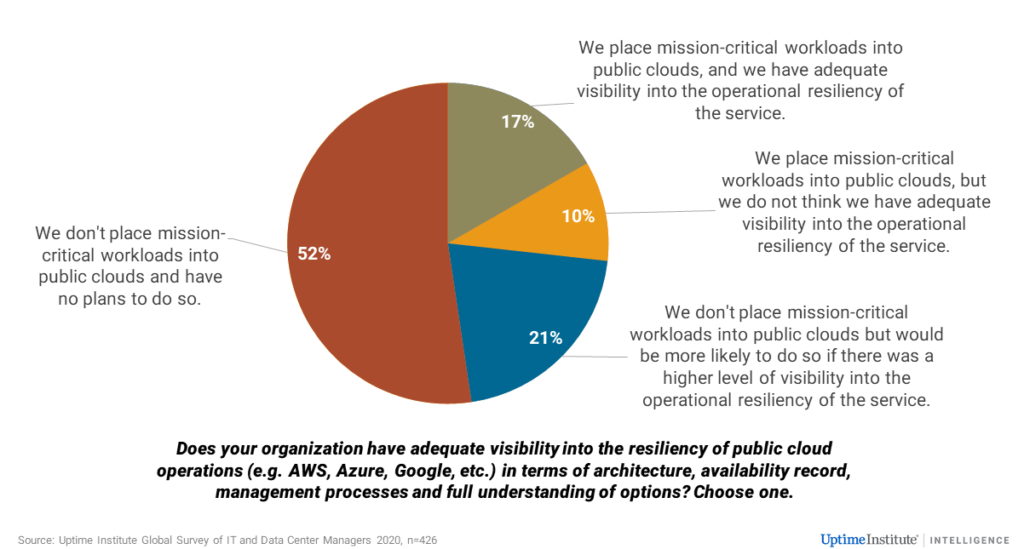
Major outages at large digital service providers point to a need for greater transparency of their operational and architectural resiliency, so customers can better assess their own risk exposure. Research from Uptime Institute Intelligence shows that only a small proportion of businesses — fewer than one in five in our study — thought they had sufficient understanding of the resilience of their cloud providers to trust them to run their mission-critical workloads (see Figure 1). Nearly a quarter said they would likely use public cloud for such workloads if they gained greater visibility into the cloud providers’ resiliency design and procedures.
Furthermore, Uptime Institute’s surveys have shown that most businesses manage a rich mix of digital infrastructures and services, spanning their own private (on-premises) data centers, leased facilities, hosted capacity, and various public cloud-powered services. This comes at the cost of added complexity, which generates risks, both known and unknown, if not managed with full visibility. In a recent survey, of those who have a view on how their services’ resilience has changed as a result of adopting hybrid environments, a strong majority reported a welcome improvement. Still, one in seven reported a decrease in overall resilience.
The bottom line is that without the possibility of verifying availability and reliability claims from cloud and other IT services providers, and without proactively mitigating the challenges that hybrid architectures pose, enterprises might be signing up to added risks to their business continuity and data security. Fastly’s customers have received a stark reminder of this growing reality at their own expense.



 2020
2020


 2020
2020 UI @ 2021
UI @ 2021