
Moscow State University Meets HPC Demands
HPC supercomputing and traditional enterprise IT facilities operate very differently
By Andrey Brechalov
In recent years, the need to solve complex problems in science, education, and industry, including the fields of meteorology, ecology, mining, engineering, and others, has added to the demand for high-performance computing (HPC). The result is the rapid development of HPC systems, or supercomputers, as they are sometimes called. The trend shows no signs of slowing, as the application of supercomputers is constantly expanding. Research today requires ever more detailed modeling of complex physical and chemical processes, global atmospheric phenomena, and distributed systems behavior in dynamic environments. Supercomputer modeling provides fine results in these areas and others, with relatively low costs.
Supercomputer performance can be described in petaflops (pflops), with modern systems operating at tens of pflops. However, performance improvements cannot be achieved solely by increasing the number of existing computing nodes in a system, due to weight, size, power, and cost considerations. As a result, designers of supercomputers attempt to improve their performance by optimizing their architecture and components, including interconnection technologies (networks) and by developing and incorporating new types of computing nodes having greater computational density per unit of area. These higher-density nodes require the use of new (or well-forgotten old) and highly efficient methods of removing heat. All this has a direct impact on the requirements for site engineering infrastructure.
HPC DATA CENTERS
Supercomputers can be described as a collection of interlinked components and assemblies—specialized servers, network switches, storage devices, and links between the system and the outside world. All this equipment can be placed in standard or custom racks, which require conditions of power, climate, security, etc., to function properly—just like the server-based IT equipment found in more conventional facilities.
Low- or medium-performance supercomputers can usually be placed in general purpose data centers and even in server rooms, as they have infrastructure requirements similar to other IT equipment, except for a bit higher power density. There are even supercomputers for workgroups that can be placed directly in an office or lab. In most cases, however, any data center designed to accommodate high power density zones should be able to host one of these supercomputers.
On the other hand, powerful supercomputers usually get placed in dedicated rooms or even buildings that include unique infrastructure optimized for a specific project. These facilities are pretty similar to general-purpose data centers. However, dedicated facilities for powerful supercomputers host a great deal of high power density equipment, packed closely together. As a result, these facilities must make use of techniques suitable for removing the higher heat loads. In addition, the composition and characteristics of IT equipment for an HPC data center are already known before the site design begins and its configuration does not change or changes only subtly during its lifetime, except for planned expansions. Thus it is possible to define the term HPC data center as a data center intended specifically for placement of a supercomputer.
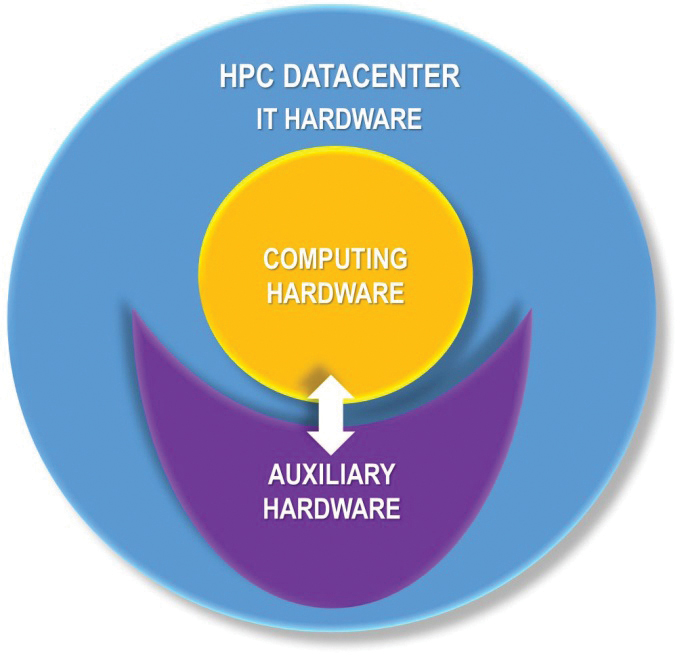
Figure 1. Types of HPC data center IT equipment
The IT equipment in a HPC data center built using the currently popular cluster-based architecture can be generally divided into two types, each having its own requirements for engineering infrastructure Fault Tolerance and component redundancy (see Figure 1 and Table 1).
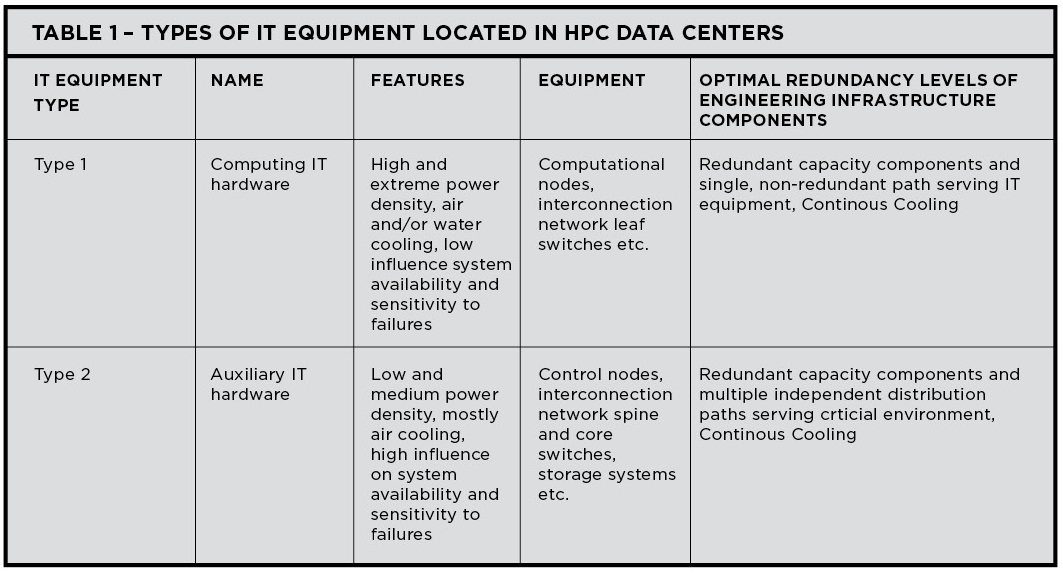
Table 1. Types of IT equipment located in HPC data centers
The difference in the requirements for redundancy for the two types of IT equipment is because applications running on a supercomputer usually have a reduced sensitivity to failures of computational nodes, interconnection leaf switches, and other computing equipment (see Figure 2). These differences enable HPC facilities to incorporate segmented infrastructures that meet the different needs of the two kinds of IT equipment.
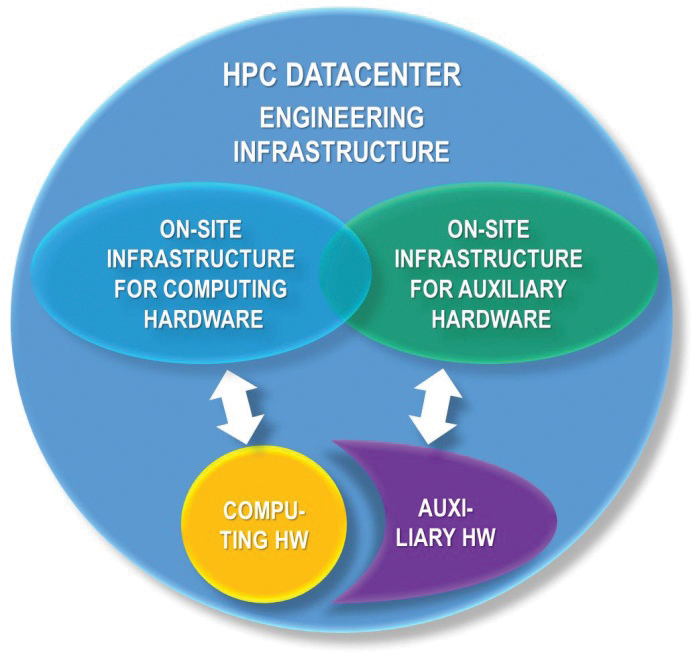
Figure 2. Generic HPC data center IT equipment and engineering infrastructure.
ENGINEERING INFRASTRUCTURE FOR COMPUTATIONAL EQUIPMENT
Supercomputing computational equipment usually incorporates cutting-edge technologies and has extremely high power density. These features affect the specific requirements for engineering infrastructure. In 2009, the number of processors that were placed in one standard 42U (19-inch rack unit) cabinet at Moscow State University’s (MSU) Lomonosov Data Center was more than 380, each having a thermal design power (TDP) of 95 watts for a total of 36 kilowatts (kW/rack). Adding 29 kW/rack for auxiliary components, such as (e.g. motherboards, fans, and switches brings the total power requirement to 65 kW/rack. Since then the power density for such air-cooled equipment has reached 65 kW/rack.
On the other hand, failures of computing IT equipment do not cause the system as a whole to fail because of the cluster technology architecture of supercomputers and software features. For example, job checkpointing and automated job restart software features enable applications to isolate computing hardware failures and the computing tasks management software ensures that applications use only operational nodes even when some faulty or disabled nodes are present. Therefore, although failures in engineering infrastructure segments that serve computational IT equipment increase the time required to perform computing tasks, these failures do not lead to a catastrophic loss of data.
Supercomputing computational equipment usually operates on single or N+1 redundant power supplies, with the same level of redundancy throughout the electric circuit to the power input. In the case of a single hardware failure, segmentation of the IT loads and supporting equipment limits the effects of the failure to only a part of IT equipment.
Customers often refuse to install standby-rated engine-generator sets, completely relying on utility power. In these cases, the electrical system design is defined by the time required for normal IT equipment shutdown and the UPS system mainly rides through brief power interruptions (a few minutes) in utility power.
Cooling systems are designed to meet similar requirements. In some cases, owners will lower redundancy and increase segmentation without significant loss of operational qualities to optimize capital expense (CapEx) and operations expense (OpEx). However, the more powerful supercomputers expected in the next few years will require the use of technologies, including partial or full liquid cooling, with greater heat removal capacity.
OTHER IT EQUIPMENT
Auxiliary IT equipment in a HPC data center includes air-cooled servers (sometimes as part of blade systems), storage systems, and switches in standard 19-inch racks that only rarely reach the power density level of 20 kW/rack. Uptime Institute’s annual Data Center Survey reports that typical densities are less than 5 kW/rack.
This equipment is critical to cluster functionality; and therefore, usually has redundant power supplies (most commonly N+2) that draw power from independent sources. Whenever hardware with redundant power is applied, the rack’s automatic transfer switches (ATS) are used to ensure the power failover capabilities. The electrical infrastructure for this equipment is usually designed to be Concurrently Maintainable, except that standby-rated engine-generator sets are not always specified. The UPS system is designed to provide sufficient time and energy for normal IT equipment shutdown.
The auxiliary IT equipment must be operated in an environment cooled to 18–27°C, (64–81°F) according to ASHRAE recommendations, which means that solutions used in general data centers will be adequate to meet the heat load generated by this equipment. These solutions often meet or exceed Concurrent Maintainability or Fault Tolerant performance requirements.
ENERGY EFFICIENCY
In recent years, data center operators have put a greater priority on energy efficiency. This focus on energy saving also applies to specialized HPC data centers. Because of the numerous similarities between the types of data centers, the same methods of improving energy efficiency are used. These include the use of various combinations of free cooling modes, higher coolant and set point temperatures, economizers, evaporative systems, and variable frequency drives and pumps as well as numerous other technologies and techniques.
Reusing the energy used by servers and computing equipment is one of the most promising of these efficiency improvements. Until recent years, all that energy had been dissipated. Moreover, based on average power usage efficiency (PUE), even efficient data centers must use significant energy to dissipate the heat they generate.
Facilities that include chillers and first-generation liquid cooling systems generate “low potential heat” [coolant temperatures of 10–15°C (50–59°F), 12–17°C (54–63°F), and even 20–25°C (68–77°F)] that can be used rather than dissipated, but doing so requires significant CapEx and OpEx (e.g., use of heat pumps) that lead to long investment return times that are usually considered unacceptable.
Increasing the heat potential of the liquid coolants improves the effectiveness of this approach, absent direct expansion technologies. And even while reusing the heat load is not very feasible in server-based spaces, there have been positive applications in supercomputing computational spaces. Increasing the heat potential can create additional opportunities to use free cooling in any climate. That allows year-round free cooling in the HPC data center is a critical requirement.
A SEGMENTED HPC DATA CENTER
Earlier this year the Russian company T-Platforms deployed the Lomonosov-2 supercomputer at MSU, using the segmented infrastructure approach. T-Platforms has experience in supercomputer design and complex HPC data center construction in Russia and abroad. When T-Platforms built the first Lomonosov supercomputer, it scored 12th in the global TOP500 HPC ratings. Lomonosov-1 has been used at 100% of its capacity with about 200 tasks waiting in job queue on average. The new supercomputer will significantly expand MSU’s Supercomputing Center capabilities.
The engineering systems for the new facility were designed to support the highest supercomputer performance, combining new and proven technologies to create an energy-efficient scalable system. The engineering infrastructure for this supercomputer was completed in June 2014, and the computing equipment is being gradually added to the system, as requested by MSU. The implemented infrastructure allows system expansion with currently available A-Class computing hardware and perspective generations of IT equipment without further investments in the engineering systems.
THE COMPUTATIONAL SEGMENT
The supercomputer is based on T-Platforms’s A-class high-density computing system and makes use of a liquid cooling system (see Figure 3). A-class supercomputers support designs of virtually any scale. The peak performance of one A-class enclosure is 535 teraflops (tflops) and a system based on it can easily be extended up to more than 100 pflops. For example, the combined performance of the five A-class systems already deployed at MSU reached 2,576 tflops in 2014 (22nd in the November 2014 TOP500) and was about 2,675 tflops in July 2015. This is approximately 50% greater than the peak performance of the entire first Lomonosov supercomputer (1,700 tflops, 58th in the same TOP500 edition). A supercomputer made of about 100 A-class enclosures would perform on par with the Tianhe-2 (Milky Way-2) system at National Supercomputer Center in Guangzhou (China) that leads the current TOP500 list at about 55 pflops.

Figure 3. The supercomputer is based on T-Platforms’s A-class high-density computing system and makes use of a liquid cooling system
All A-class subsystems, including computing and service nodes, switches, and cooling and power supply equipment, are tightly integrated in a single enclosure as modules with hot swap support (including those with hydraulic connections). The direct liquid cooling system is the key feature of the HPC data center infrastructure. It almost completely eliminates air as the medium of heat exchange. This solution improves the energy efficiency of the entire complex by making these features possible:
• IT equipment installed in the enclosure has no fans
• Heat from the high-efficiency air-cooled power supply units (PSU) is removed using water/air heat exchangers embedded in the enclosure
• Electronic components in the cabinet do not require computer room air for cooling
• Heat dissipated to the computer room is minimized because the cabinet is sealed and insulated
• Coolant is supplied to the cabinet at cabinet at 44°C (111°F) with up to 50°C (122°F) outbound under full load, which enables year-round free cooling at ambient summer temperatures of up to 35°C (95°F) and the use of dry coolers without adiabatic systems (see Figure 4)


Figure 4. Coolant is supplied to the auxiliary IT cabinets at 44°C (50°C outbound under full load), which enables year-round free cooling at ambient summer temperatures of up to 35°C and the use of dry coolers without adiabatic systems
In addition noise levels are also low because liquid cooling eliminates powerful node fans that generate noise in air-cooled systems. The only remaining fans in A-Class systems are embedded in the PSUs inside the cabinets, and these fans are rather quiet. Cabinet design contains most of the noise from this source.
INFRASTRUCTURE SUPPORT
The power and cooling systems for Lomonosov-2 follow the general segmentation guidelines. In addition, they must meet the demands of the facility’s IT equipment and engineering systems at full load, which includes up to 64 A-class systems (peak performance over 34 pflops) and up to 80 auxiliary equipment U racks in 42U, 48U, and custom cabinets. At full capacity these systems require 12,000-kW peak electric power capacity.
Utility power is provided by eight 20/0.4-kV substations, each having two redundant power transformers making a total of 16 low-voltage power lines with a power limit of 875 kW/line in normal operation.
Although no backup engine-generator sets have been provisioned, at least 28% of the computing equipment and 100% of auxiliary IT equipment is protected by UPS providing at least 10 minutes of battery life for all connected equipment.
The engineering infrastructure also includes two independent cooling systems: a warm-water, dry-cooler type for the computational equipment and a cold-water, chiller system for auxiliary equipment. These systems are designed for normal operation in temperatures ranging from -35 to+35°C (-31 to +95°F) with year-round free cooling for the computing hardware. The facility also contains an emergency cooling system for auxiliary IT equipment.
The facility’s first floor includes four 480-square-meters (m2) rooms for computing equipment (17.3 kW/m2) and four 280-m2 rooms for auxiliary equipment (3 kW/m2) with 2,700 m2 for site engineering rooms on an underground level.
POWER DISTRIBUTION
The power distribution system is built on standard switchboard equipment and is based on the typical topology for general data centers. In this facility, however, the main function of the UPS is to ride through brief blackouts of the utility power supply for select computing equipment (2,340 kW), all auxiliary IT equipment (510 kW), and engineering equipment systems (1,410 kW). In the case of a longer blackout, the system supplies power for proper shutdown of connected IT equipment.
The UPS system is divided into three independent subsystems. The first is for computing equipment, the second is for auxiliary equipment, and the third is for engineering systems. In fact, the UPS system is deeply segmented because of the large number of input power lines. This minimizes the impact of failures of engineering equipment on supercomputer performance in general.
The segmentation principle is also applied to the physical location of the power supply equipment. Batteries are placed in three separate rooms. In addition, there are three UPS rooms and one switchboard room for the computing equipment that is unprotected by UPS. Figure 5 shows one UPS-battery room pair.
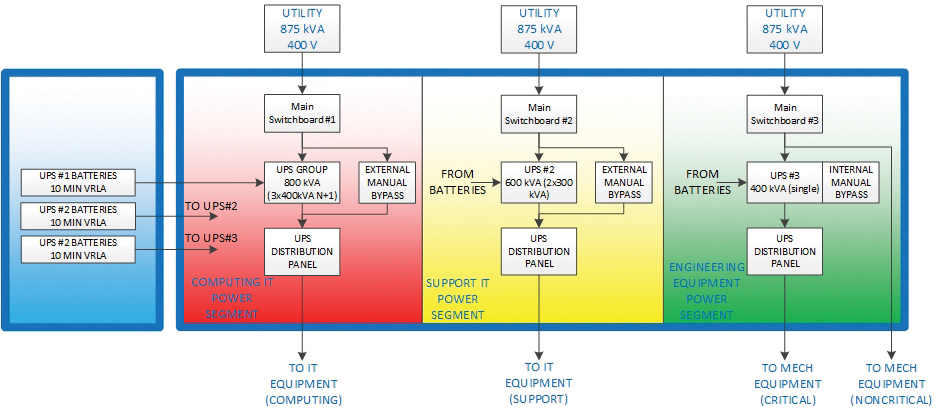
Figure 5. A typical pair of UPS-battery rooms
Three, independent, parallel UPS, each featuring N+1 redundancy (see Figure 6), feed the protected computing equipment. This redundancy, along with bypass availability and segmentation, simplifies UPS maintenance and the task of localizing a failure. Considering that each UPS can receive power from two mutually redundant transformers, the overall reliability of the system meets the owner’s requirements.
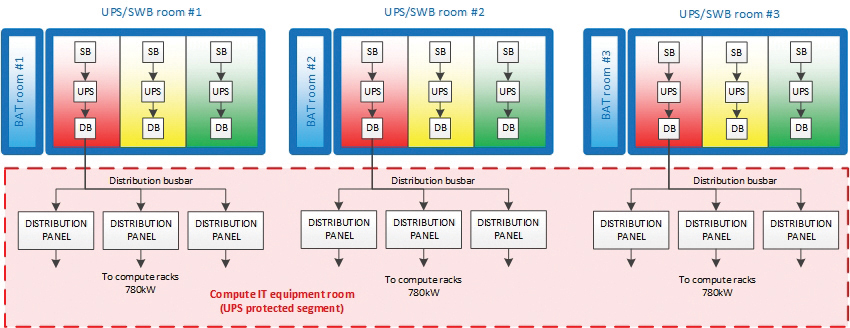
Figure 6. Power supply plan for computing equipment
Three independent parallel UPS systems are also used for the auxiliary IT equipment because it requires greater failover capabilities. The topology incorporates a distributed redundancy scheme that was developed in the late 1990s. The topology is based on use of three or more UPS modules with independent input and output feeders (see Figure 7).
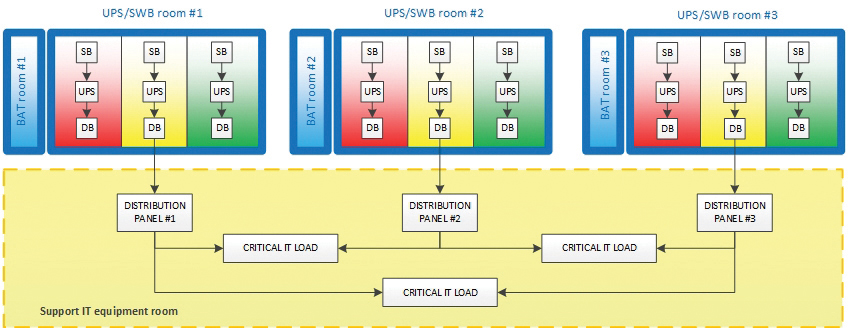
Figure 7. Power supply for auxiliary equipment
This system is more economical than a 2N-redundant configuration while providing the same reliability and availability levels. Cable lines connect each parallel UPS to the auxiliary equipment computer rooms. Thus, the computer room has three UPS-protected switchboards. The IT equipment in these rooms, being mostly dual fed, is divided into three groups, each of which is powered by two switchboards. Single-feed and N+1 devices are connected through a local rack-level ATS (see Figure 8).

Figure 8. Single-feed and N+1-redundant devices are connected through a local rack-level ATS
ENGINEERING EQUIPMENT
Some of the engineering infrastructure also requires uninterrupted power in order to provide the required Fault Tolerance. The third UPS system meets this requirement. It consists of five completely independent single UPSs. Technological redundancy is fundamental. Redundancy is applied not to the power lines and switchboard equipment but directly to the engineering infrastructure devices.
The number of UPSs in the group (Figure 9 shows three of five) determines the maximum redundancy to be 4+1. This system can also provide 3+2 and 2N configurations). Most of the protected equipment is at N+1 (see Figure 9).
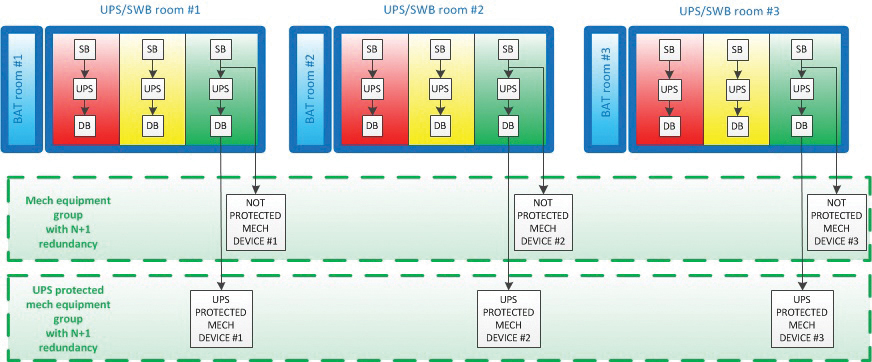
Figure 9. Power supply for engineering equipment
In general, this architecture allows decommissioning of any power supply or cooling unit, power line, switchboard, UPS, etc., without affecting the serviced IT equipment. Simultaneous duplication of power supply and cooling system components is not necessary.
OVERALL COOLING SYSTEM
Lomonosov-2 makes use of a cooling system that consists of two independent segments, each of which is designed for its own type of IT equipment (see Table 2). Both segments make use of a two-loop scheme with plate heat exchangers between loops. The outer loops have a 40% ethylene-glycol mixture that is used for coolant. Water is used in the inner loops. Both segments have N+1 components (N+2 for dry coolers in the supercomputing segment).

Table 2. Lomonosov makes use of a cooling system that consists of two independent segments, each of which is designed to meet the different requirements of the supercomputing and auxiliary IT equipment.
This system, designed to serve the 64 A-class enclosures, has been designated the hot-water segment. Its almost completely eliminates the heat from extremely energy-intensive equipment without chillers (see Figure 10). Dry coolers dissipate all the heat that is generated by the supercomputing equipment up to ambient temperatures of 35°C (95°F). Power is required only for the circulation pumps of both loops, dry cooler fans, and automation systems.
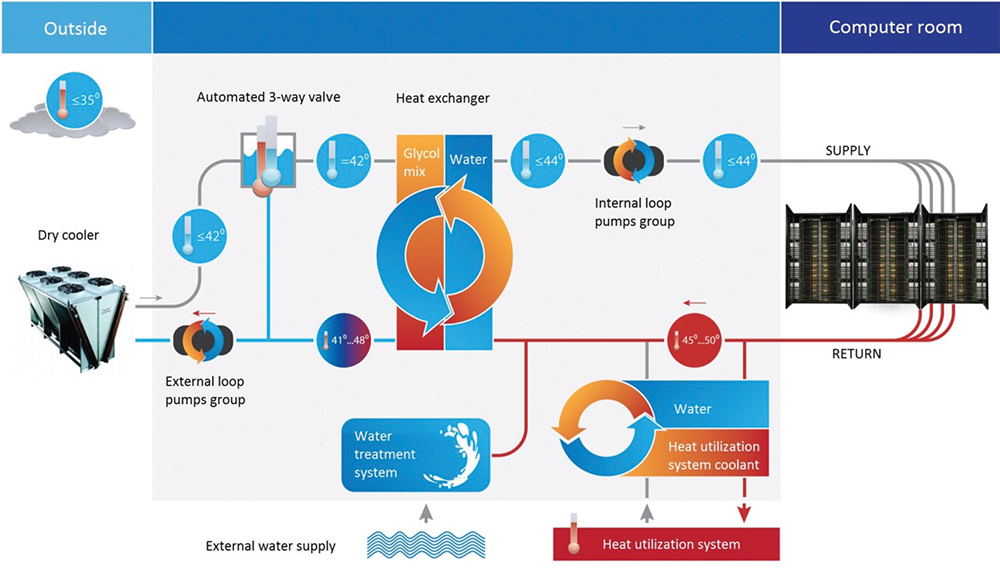
Figure 10. The diagram shows the cooling system’s hot water segment.
Under full load and in the most adverse conditions, the instant PUE would be expected to be about 1.16 for the fully deployed system of 64 A-class racks (see Figure 11).

Figure 11. Under full load and under the most adverse conditions, the instant PUE (power utilization efficiency would be expected to be about 1.16 for the fully deployed system of 64 A-class racks)
The water in the inner loop has been purified and contains corrosion inhibitors. It is supplied to computer rooms that will contain only liquid-cooled computer enclosures. Since the enclosures do not use computer room air for cooling, the temperature in these rooms is set at 30°C (86°F) and can be raised to 40°C (104°F) without any influence on the equipment performance. The inner loop piping is made of PVC/CPVC (polyvinyl chloride/chlorinated polyvinyl chloride) thus avoiding electrochemical corrosion.
COOLING AUXILIARY IT EQUIPMENT
It is difficult to avoid using air-cooled IT equipment, even in a HPC project, so MSU deployed a separate cold-water [12–17°C (54–63°F)] cooling system. The cooling topology in these four spaces is almost identical to the hot-water segment deployed in the A-class rooms, except that chillers are used to dissipate the excess heat from the auxiliary IT spaces to the atmosphere. In the white spaces, temperatures are maintained using isolated Hot Aisles and in-row cooling units. Instant PUE for this isolated system is about 1.80, which is not a particularly efficient system (see Figure 12).

Figure 12. In white spaces, temperatures are maintained using isolated hot aisles and in-row cooling units.
If necessary, some of the capacity of this segment can be used to cool the air in the A-class computing rooms. The capacity of the cooling system in these spaces can meet up to 10% of the total heat inflow in each of the A-class enclosures. Although sealed, they still heat the computer room air through convection. But in fact, passive heat radiation from A-class enclosures is less than 5% of the total power consumed by them.
EMERGENCY COOLING
An emergency-cooling mode exists to deal with utility power input blackouts, when both cooling segments are operating on power from the UPS. In emergency mode, each cooling segment has its own requirements. As all units in the first segment (both pump groups, dry coolers, and automation) are connected to the UPS, the system continues to function until the batteries discharge completely.
In the second segment, the UPS services only the inner cooling loop pumps, air conditioners in computer rooms, and automation equipment. The chillers and outer loop pumps are switched off during the blackout.
Since the spaces allocated for cooling equipment are limited, it was impossible to use a more traditional method of stocking cold water at the outlet of the heat exchangers (see Figure 13). Instead, the second segment of the emergency system features accumulator tanks with water stored at a lower temperature than in the loop [about 5°C (41°F) with 12°C (54°F) in the loop] to keep system parameters within a predetermined range. Thus, the required tank volume was reduced to 24 cubic meters (m3) instead of 75 m3, which allowed the equipment to fit in the allocated area. A special three-way valve allows mixing of chilled water from the tanks into the loop if necessary. Separate small low-capacity chillers (two 55-kW chillers) are responsible for charging the tanks with cold water. The system charges the cold-water tanks in about the time it takes to charge the UPS batteries.

Figure 13. Cold accumulators are used to keep system parameters within a predetermined range.
MSU estimates that segmented cooling with a high-temperature direct water cooling segment reduces its total cost of ownership by 30% compared to data center cooling architectures based on direct expansion (DX) technologies. MSU believes that this project shows that combining the most advanced and classical technologies and system optimization allows significant savings on CapEx and OpEx while keeping the prerequisite performance, failover, reliability and availability levels.

Andrey Brechalov
Andrey Brechalov is Chief Infrastructure Solutions Engineer of T-Platforms, a provider of high performance computing (HPC) systems, services, and solutions headquartered in Moscow, Russia. Mr. Brechalov has responsibility for building engineering infrastructures for supercomputers SKIF K-1000, SKIF Cyberia, and MSU Lomonosov-2 as well as smaller supercomputers by T-Platforms. He has worked for more than 20 years in computer industry including over 12 years in HPC and specializes in designing, building, and running supercomputer centers.
 2019, Getty
2019, Getty





