
Outage Reporting in Financial Services
In the movie “Mary Poppins,” Mr. Banks sings that a British bank must be run with precision, and that “Tradition, discipline and rules must be the tools.” Otherwise, he warns, “Disorder! Chaos!” will ensue.
One rule, introduced by the UK Financial Conduct Authority (FCA) in 2018, suggests that disorder and chaos might be quite common in the IT departments of many UK banks. The rule introduced the mandatory reporting of online service disruptions caused by IT problems for retail banks. The first year’s figures, published this summer, show that banks, on average, suffered an IT outage or security issue nearly every month.
The numbers (shown in the table below) are far higher than any published elsewhere or previously. One bank, Barclays, averaged an incident nearly every ten days. But all the big banks suffered frequent problems. Given this, it is no surprise that the UK Treasury Select Committee has called for action, and the Bank of England is planning on introducing new operational resilience rules for all financial institutions operating in the UK.
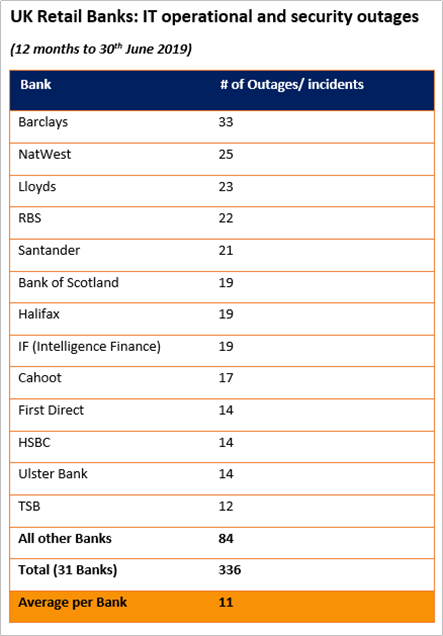
Source: UK Financial Conduct Authority
There may be certain mitigating factors relating to the retail banking figures: many of the banks are large and have multiple services, and some of the banks have common ownership or shared systems, so there may some “double counting” of underlying problems. And the data has grouped security incidents with IT availability problems, which has boosted the overall numbers.
Even so, there is clearly an issue in retail banking/financial services that is similar to the one affecting airlines, which we discussed in our “Creeping Criticality Note” (available to Uptime Institute Network members). The growing demand for 24-hour availability — at ever increasing scale — and the need to support ever more services is running ahead of some companies’ ability to deliver it. This seems to be affecting many financial services organizations. The FCA, which has responsibility for all UK financial services (such as insurance, pensions, etc.), recently said the number of “operational resilience” breaks reported increased to 916 for the year 2018-19 from 229 the year before – a 300% increase.
The FCA’s Director of Supervision Meghan Butler made two important observations when the numbers were published: First, a substantial number of new incidents were caused by IT and software issues (including, we assume, data center power/networking) and not so much by cyber-attacks. She noted the need for better management and processes. And second, the increase, while real, is also to do with the number of incidents being reported.
The last point is critical: Dozens of financial services giants and hundreds of innovative fintech startups call the UK home. Is this a uniquely UK problem? Is IT in this sector is particularly bad? There may be — indeed, there are known to be — problems with modernizing huge, legacy infrastructure while in flight. But many US banks, for example, have suffered similar issues.
Undoubtedly, a big proportion of the rise is due to the fact that the FCA now insists that incidents are reported. Outage reporting across almost all industries is at best ad hoc — notwithstanding confidential reporting systems run by the Uptime Institute Network (the Abnormal Incident Report, or AIR, database) and the Data Center Incident Reporting Network (DCIRN), an independent body set up in 2017 by veteran data center designer Ed Ansett. Even allowing for media reports, many also tracked by Uptime, the vast majority of outages, even at major firms, are never reported to anyone, so the lessons cannot be learned. While outages at consumer-facing internet services can be spotted by web-based outage reporting services using software tools, often there no real details other than data that points to a loss or slowdown in service.
It has often been suggested that for lessons to be shared, mandatory reporting of outages — in detail — is needed, at least by large or important organizations or services. The FCA’s data supports the view that many outages are hidden. Now they have surfaced, the next question is, How can the lessons of the failures can be more openly and widely shared?
———————————————————————————————————————————–
More information on this topic is available to members of the Uptime Institute Network which can be found here.






 2019
2019

