Users unprepared for inevitable cloud outages
Organizations are becoming more confident in using the cloud for mission-critical workloads — partly due to a perception of improved visibility into operational resiliency. But many users aren’t taking basic steps to ensure their mission-critical applications can endure relatively frequent availability zone outages.
Data from the 2022 Uptime Institute annual survey reflects this growing confidence in public cloud. The proportion of respondents not placing mission-critical workloads into a public cloud has now dropped from 74% (2019) to 63% (2022), while those saying they have adequate visibility into the resiliency of public-cloud services has risen from 14% to 21%.
However, other survey data suggests cloud users’ confidence may be misplaced. Cloud providers recommend that users distribute their workloads across multiple availability zones. An availability zone is a logical data center, often understood to have redundant and separate power and networking. Cloud providers make explicitly clear that zones will suffer outages occasionally — their position being that users must architect their applications to handle the loss of an availability zone.
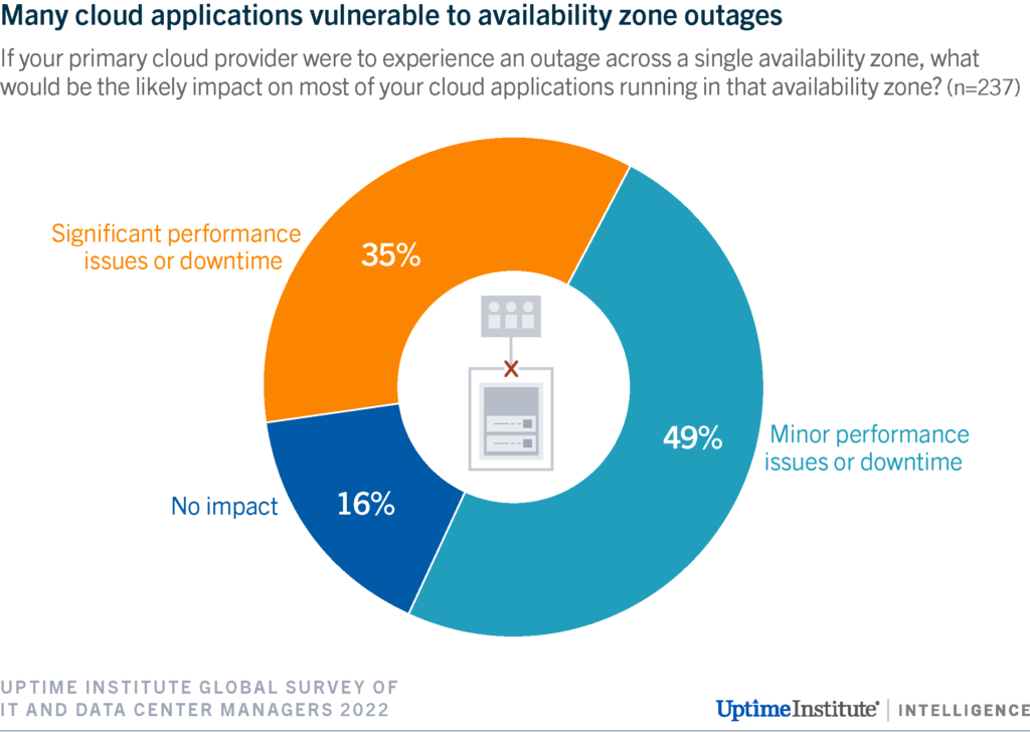
Zone outages are relatively common: 35% of respondents said the loss of an availability zone would result in significant performance issues. Only 16% of those surveyed said that the loss of an availability zone would have no impact on their cloud applications (see Figure 1).
This presents a clear contradiction. Users appear to be more confident that the public cloud can handle mission-critical workloads, yet over a third of users are architecting applications vulnerable to relatively common availability zone outages. This contradiction is due to a lack of clarity on the respective roles and responsibilities of provider and user.
Who is at fault if an application goes down as a result of a single availability zone outage? This data point would appear to reflect the lack of clarity on roles and responsibilities: half of respondents to Uptime’s annual survey believe this to be primarily the cloud provider’s fault, while the other half believe responsibility lies with the user in having failed to architect the application to avoid such downtime.
The provider is, of course, responsible for the operational resiliency of its data centers. But cloud providers neither state nor guarantee that availability zones will be highly available. On which basis, why do users assume that a single availability zone will provide the resiliency their application requires?
This misunderstanding might, at least in part, be due to the simplistic view that the cloud is just someone else’s computer, in someone else’s data center: but this is not the case. A cloud service is a complex combination of data center, hardware, software and people. Services will fail from time to time due to unexpected behavior arising from the complexity of interacting systems, and people.
Accordingly, organizations that want to achieve high availability in the cloud must architect their applications to endure frequent outages of single availability zones. Lifting and shifting an application from an on-premises server to a cloud virtual machine might reduce resiliency if the application is not rearchitected to work across cloud zones.
As cloud adoption increases, the impact of outages is likely to grow as a significantly higher number of organizations rely on cloud computing for their applications. While many will architect their applications to weather occasional outages, many are not yet fully prepared for inevitable cloud service failures and the subsequent impact on their applications.
 2020
2020


 2019
2019

 Uptime Institute, 2019
Uptime Institute, 2019
