
Cloud resiliency: plan to lose control of your planes
Cloud providers divide the technologies that underpin their services into two ”planes”, each with a different architecture and availability goal. The control plane manages resources in the cloud; the data plane runs the cloud buyer’s application.
In this Update, Uptime Institute Intelligence presents research that shows control planes have poorer availability than data planes. This presents a risk to applications built using cloud-native architectures, which rely on the control plane to scale during periods of intense demand. We show how overprovisioning capacity is the primary way to reduce this risk. The downside is an increase in costs.
Data and control planes
An availability design goal is an unverified claim of service availability that is neither guaranteed by the cloud provider nor independently confirmed. Amazon Web Services (AWS), for example, states 99.99% and 99.95% availability design goals for many of its services’ data planes and control planes. Service level agreements (SLAs), which refund customers a proportion of their expenditure when resources are not available, are often based on these design goals.
Design goals and SLAs differ between control and data planes because each plane performs different tasks using different underlying architecture. Control plane availability refers to the availability of the mechanism it uses to manage and control services, such as:
- Creating a virtual machine or other resource allocation on a physical server.
- Provisioning a virtual network interface on that resource so it can be accessed over the network.
- Installing security rules on the resource and setting access controls.
- Configuring the resource with custom settings.
- Hosting an application programming interface (API) endpoint so that users and code can programmatically manage resources.
- Offering a management graphical user interface for operations teams to administrate their cloud estates.
The data plane availability refers to the availability of the mechanism that executes a service, such as:
- Routing packets to and from resources.
- Writing and reading to and from disks.
- Executing application instructions on the server.
In practice, such separation means a control plane could be unavailable, preventing services from being created or turned off, while the data plane (and, therefore, the application) continues to operate.
Data plane and control plane issues can impact business, but a data plane problem is usually considered more significant as it would immediately affect customers already using the application. The precise impact of a data plane or control plane outage depends on the application architecture and the type of problem.
Measuring plane availability
Providers use the term “region” to describe a geographical area that contains a collection of independent availability zones (AZs), which are logical representations of data center facilities. A country may have many regions, and each region typically has two or three AZs. Cloud providers state that users must architect their applications to be resilient by distributing resources across AZs and/or regions.
To compare the respective availability of resilient cloud architectures (see Comparative availabilities of resilient cloud architectures), Uptime Institute used historical cloud provider status updates from AWS, Google Cloud and Microsoft Azure to determine historical availabilities for a simple load balancer application deployed in three architectures:
- Two virtual machines deployed in the same AZ (“single-zone”).
- Two virtual machines deployed in different AZs in the same region (“dual-zone”).
- Two virtual machines deployed in different AZs in different regions (“dual-region”).
Figure 1 shows the worst-case availabilities (i.e., the worst availability of all regions and zones analyzed) for the control planes and data planes in these architectures.
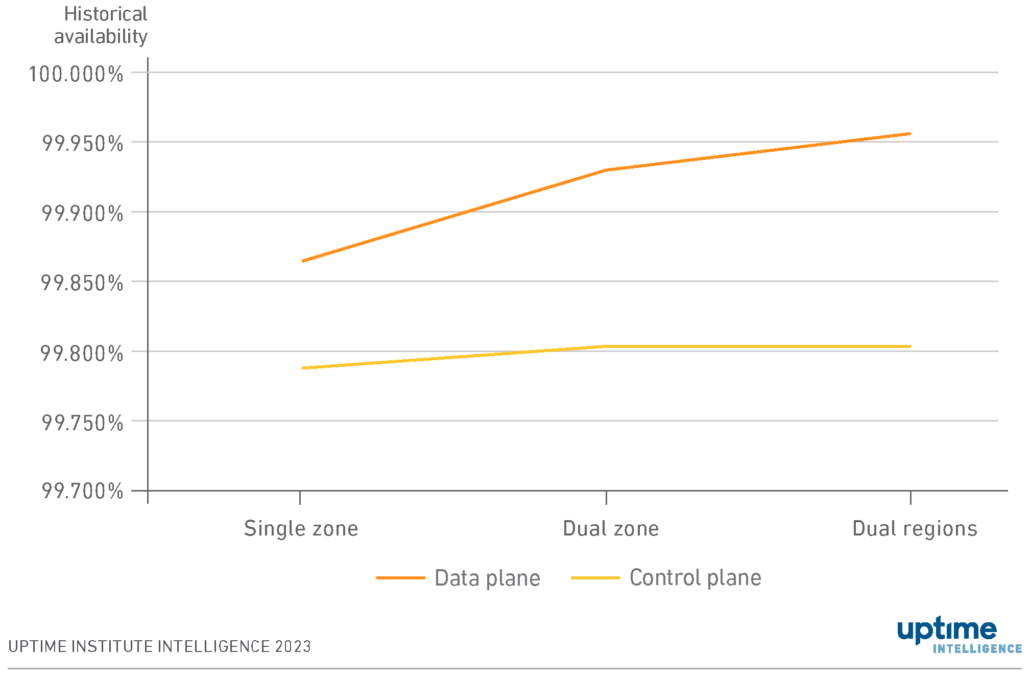
Unsurprisingly, even in the worst-case scenario, a dual-region architecture is the most resilient, followed by a dual-zone architecture.
The data plane has a significantly higher availability than the control plane. In the dual region category, the data plane had an availability of 99.96%, equivalent to 20 minutes of monthly downtime. The control plane had an availability of 99.80%, equal to 80 minutes of downtime — four times that of the data plane. This difference is to be expected considering the different design goals and SLAs associated with control and data planes. Our research found that control plane outages do not typically happen at the same time as data plane outages.
However, availability in the control plane is far more consistent than in the data plane and isn’t greatly affected by choice of architecture. This consistency is because the cloud provider manages availability and resiliency — the control plane effectively acts as a platform as a service (PaaS). Suppose an organization hosts an application in a single zone. In that case, the application programming interfaces (APIs) — and the management interface used to administer that application — are managed by the cloud provider and hosted in multiple zones and regions, despite the application only being hosted in a single zone.
The warning for cloud customers here is that the control plane is more likely to be a point of failure than the application, and little can be done to make the control plane more resilient.
Assessing the risk
The crucial question organizations should seek to answer during risk assessments is, “What happens if we cannot add or remove resources to our application?”
For static applications that can’t scale, a control plane outage is often more of an inconvenience than a business-critical problem. Some maintenance tasks may be delayed until the outage is over, but the application will continue to run normally.
For cloud-native scalable applications, the risk is more considerable. A cloud-native application should be able to scale up and down dynamically, depending on demand, which involves creating (or terminating) a resource and configuring it to work with the application that is currently executing.
Scaling capacity in response to application demand is typically done using one or a combination of three methods:
- Automatically, using cloud provider autoscaling services that detect a breach of a threshold of a metric (e.g., CPU utilization).
- Automatically from an application, where code communicates with a cloud provider’s API.
- Manually, by an administrator using a management portal or API.
The management portal, the API, the autoscaler service, and the creation or termination of the resource may all be part of the control plane.
If the application has been scaled back to cut costs but faces increased demand, any of these mechanisms can increase capacity. But if they have failed, the application will continue to run but will not accommodate the additional demand. In this scenario, the application may continue to service existing end users satisfactorily, but additional end users may have to wait. In the worst case, the application might fail catastrophically because of oversubscription.
Addressing the risk
The only real redress for this risk is to provision a buffer of capacity on the services that support the application. If a demanding period requires more resources, the application can immediately use this buffer, even if the control plane is out of service.
Having a buffer is a sensible approach for many reasons. Suppose other issues cause delays in provisioning capacity, for example an AZ fails or increased demand in a region causes a lack of capacity. A buffer will prevent a time lag between end-user demand and resource access.
The question is how much buffer capacity to provision. A resilient architecture often automatically includes suitable buffer capacity because the application is distributed across AZs or regions. If an application is split across, say, two AZs, it is probably designed with enough buffer on each virtual machine to enable the application to continue seamlessly if one of the zones is lost. Each virtual machine has a 50% load, with the unused 50% available if the other AZ suffers an outage. In this case, no new resources can be added if the control plane fails, but the application is already operating at half load and has excess capacity available. Of course, if the other AZ fails at the same time as a control plane outage, the remaining zone will face a capacity squeeze.
Similarly, databases may be deployed across multiple AZs using an active-active or active-failover configuration. If an AZ fails, the other database will automatically be available to support transactions, regardless of the control plane functionality.
Organizations need to be aware that this is their risk to manage. The application must be architected for control and data plane failures. Organizations also need to be mindful that there is a cost implication. As detailed in our Comparative availabilities of resilient cloud architectures report, deploying across multiple zones increases resiliency, but also increases costs by 43%. Carbon emissions, too, rise by 83%. Similarly, duplicating databases across zones increases availability — but at a price.
Summary
Organizations must consider how their applications will perform if a control plane failure prevents them adding, terminating or administrating cloud resources. The effect on static applications will be minimal because such applications can’t scale up and down in line with changing demand. However, the impact on cloud-native applications may be substantial because the application may struggle under additional demand without the capacity to scale.
The simplest solution is to provide a buffer of unused capacity to support unexpected demand. If additional capacity can’t be added because of a control plane outage, the buffer can meet additional demand in the interim.
The exact size of the buffer depends on the application and its typical demand pattern. However, most applications will already have a buffer built in so they can respond immediately to AZ or region outages. Often, this buffer will be enough to manage control plane failure risks.
Organizations face a tricky balancing act. Some end users might not get the performance they expect if the buffer is too small. If the buffer is too large, the organization pays for capacity it doesn’t need.

