If You Can’t Buy Effective DCIM, Build It
After commercial DCIM offerings failed to meet RELX Group’s requirements, the team built its own DCIM tool based on the existing IT Services Management Suite
By Stephanie Singer
What is DCIM? Most people might respond “data center infrastructure management.” However, simply defining the acronym is not enough. The meaning of DCIM is greatly different for each person and each enterprise.
At RELX Group and the data centers managed by the Reed Elsevier Technology Services (RETS) team, DCIM is built on top of our configuration management database (CMDB) and provides seamless, automated interaction between the IT and facility assets in our data centers, server rooms, and telco rooms. These assets are mapped to the floor plans and electrical/mechanical support systems within these locations. This arrangement gives the organization the ability to manage its data centers and internal customers in one central location. Additionally, DCIM components are fully integrated with the company’s global change and incident management processes for holistic management and accuracy.
A LITTLE HISTORY
So what does this all mean? Like many of our colleagues, RETS has consulted with several DCIM providers over the years. Many of them enthusiastically promised a solution for our every need, creating excitement at the prospect of a state-of-the art system for a reasonable cost. But, as we all know, the devil is in the details.
I grew up in this space and have personally been on this road since the early 1980s. Those of you who have been on the same journey will likely remember using the Hitachi Tiger tablet with AutoCAD to create equipment templates. We called it “hardware space planning” at the time, and it was a huge improvement over the template cutouts from IBM, which we had to move around manually on an E-size drawing.
Many things have changed over the last 30 years, including the role of vendors in our operation. Utilizing DCIM vendors to help achieve infrastructure goals has become a common practice in many companies, with varying degrees of success. This has most certainly been a topic at every Uptime Institute Symposium as peers shared what they were doing and sought better go-forward approaches and planning.
OUR FIRST RUN AT PROCURING DCIM
Oh how I coveted the DCIM system my friend was using for his data center portfolio at a large North America-based retail organization. He and his team helpfully provided real world demos and resource estimates to help us construct the business case that was approved, including the contract resources for a complete DCIM installation. We were able to implement the power linking for our assets in all our locations. Unfortunately, the resource dollars did not enable us to achieve full implementation with the cable management. I suspect many of you reading this had similar experiences.
Nevertheless, we had the basic core functionality and a DCIM system that met our basic needs. We ignored inefficiencies, even though it took too many clicks to accomplish the tasks at hand and we still had various groups tracking the same information in different spreadsheets and formats across the organization.
About 4-1/2 years after implementation, our vendor reported the system we were using would soon be at end of life. Of course, they said, “We have a new, bigger, better system. Look at all the additional features and integration you can have to expand and truly have everything you need to run your data centers, manage your capacities, and drive costs out.”
Digging deeper, we found that driving cost out was not truly obtainable when we balanced the costs of fully collating the data, building the integration with other systems and processes, and maintaining the data and scripting that was required. With competing priorities and the drive for cost efficiencies, we went back to the drawing board and opened the DCIM search to other providers once again.
STARTING OVER WITH DCIM MARKET RESEARCH
The DCIM providers we looked at had all the physical attributes tied to the floor and rack space, cable management, asset life cycle, capacity planning, and various levels for the electrical/mechanical infrastructure. These tools all integrated with power quality and building management and automation systems, each varying slightly in their approach and data output. And many vendors offered bi-directional data movement from the service management tool suite and CMDB.
But our findings revealed potential problems such as duplicate and out-of-sync data. This was unacceptable. We wanted all the features our DCIM providers promised without suffering poor data quality. We also wanted the DCIM to fully integrate with our change and incident management systems so we could look holistically at potential root causes of errors. We wanted to see where the servers were located across the data center, if they were in alarm, when maintenance was occurring, and whether a problem was resolved. We wanted the configuration item attributes for maintenance, end of life, contract renewals, procedures, troubleshooting guidelines, equipment histories, business ownerships, and relationships to be 100% mapped globally.
RETS has always categorized data center facilities as part of IT, separate from Corporate Real Estate. Therefore, all mechanical and electrical equipment within our data center and server rooms are configuration items (CI) as well. This includes generators, switchgear, uninterruptible power systems (UPS), power distribution units (PDU), remote power panels (RPP), breakers, computer room air conditioners (CRAC), and chillers. Breaking away from the multiple sources we had been using for different facility purposes greatly improved our overall grasp on how our facility team could better manage our data centers and server rooms.
NEW PARADIGM
This realization caused us to ask ourselves: What if we flipped the way DCIM is constructed? What if it is built -on top of the Service Management Suite, so it is truly a full system that integrates floor plans, racks, and power distribution to the assets within the CMDB? Starting with this thought, we aggressively moved forward to completely map the DCIM system we currently had in place and customize our existing Service Management Suite.
We started this journey in October 2014 and followed a Scrum software development process. Scrum is an iterative and incremental agile software development methodology. The 2-week sprints and constant feedback that provided useful functionality were keys to this approach. It was easy to adapt quickly to changes in understanding.
Another important part of Scrum is to have a complete team set up with a subject matter expert (SME) to serve as the product owner to manage the backlog of features. Other team members included the Service Management Suite tool expert to design forms and tables, a user interface (UI) expert to design the visualization and a Scrum master to manage the process. A web service expert joined the team to port the data from the existing DCIM system into the CMDB. All these steps were critical; however, co-locating the team with a knowledgeable product owner to ensure immediate answers and direction to questions really got us off and running!
We created our wish list of requirements, prioritizing those that enabled us to move away from our existing DCIM system.
Interestingly enough, we soon learned from our vendor that the end of life for our current 4-1/2 year-old DCIM system would be extended because of the number of customers that remained on that system. Sound familiar? The key was to paint the vision of what we wanted and needed it to be, while pulling a creative and innovative group of people together to build a roadmap for how we were going to get there.
It was easy to stay focused on our goals. We avoided scope creep by aligning our requirements with the capabilities that our existing tool provided. The requirements and capabilities that aligned were in scope. Those that didn’t were put on a list for future enhancements. Clear and concise direction!
The most amazing part was that using our Service Management Suite was providing many advantages. We were getting all the configuration data linked and a confidence in the data accuracy. This created excitement across the team and the “wish” list of feature requests grew immensely! In addition to working on documented requests, our creative and agile team came back with several ideas for features we had not initially contemplated, but that made great business sense. Interestingly enough, we achieved many of these items so easily we had achieved a significantly advanced tool with the automation features we leveraged by the time we went live in our new system.
FEATURES
Today we can pull information by drilling down on a oor plan to a device that enables us to track the business owner, equipment relationships, application to infrastructure mapping, and application dependencies. This information allows us to really understand the impacts of adding, moving, modifying, or decommissioning within seconds. It provides real-time views for our business partners when power changes occur, maintenance is scheduled, and if a device alarming is in effect (see Figure 1).

Figure 1. DCIM visualization
The ability to tie in CIs to all work scheduled through our Service Management Suite change requests and incidents provides a global outlook on what is being performed within each data center, server room, and telco room, and guarantees accuracy and currency. We turned all electrical and mechanical devices into CIs and assigned them physical locations on our floor plans (see Figure 2).
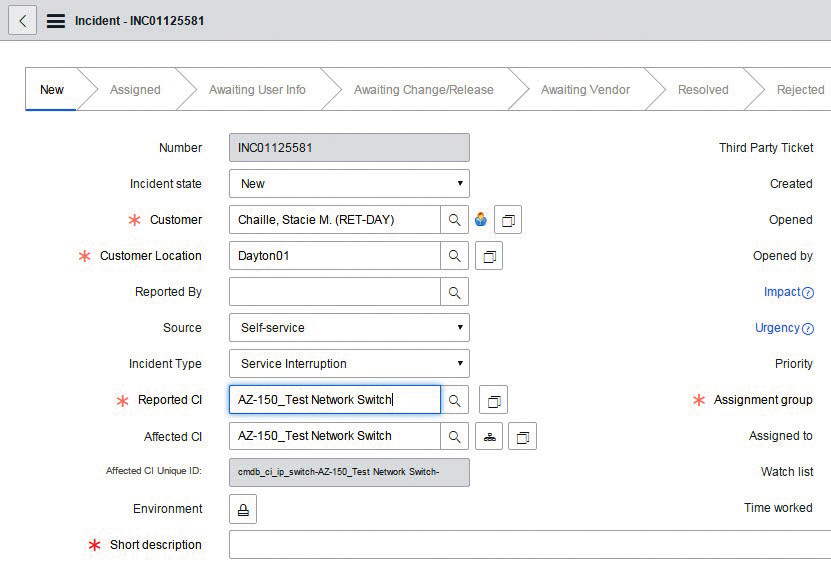
Figure 2. Incident reporting affected CI
Facility work requests are incorporated into the server install and decommissioning workflow. Furthermore, auto discovery alerts us to devices that are new to the facility, so we are aware if something was installed outside of process.
If an employee needs to add a new model to the floor plan we have a facility management form for that process, where new device attributes can be specified and created by users within seconds.
Facility groups can modify
floor plans directly from the visualization providing dynamic updates to all users, Operations can monitor alarming and notifications 24×7 for any CI, and IT teams can view rack elevations for any server rack or storage array (see Figure 3).
Power management, warranty tracking, maintenance, hardware dependencies, procedures, equipment relationships, contract management, equipment histories can all be actively maintained all within one system.
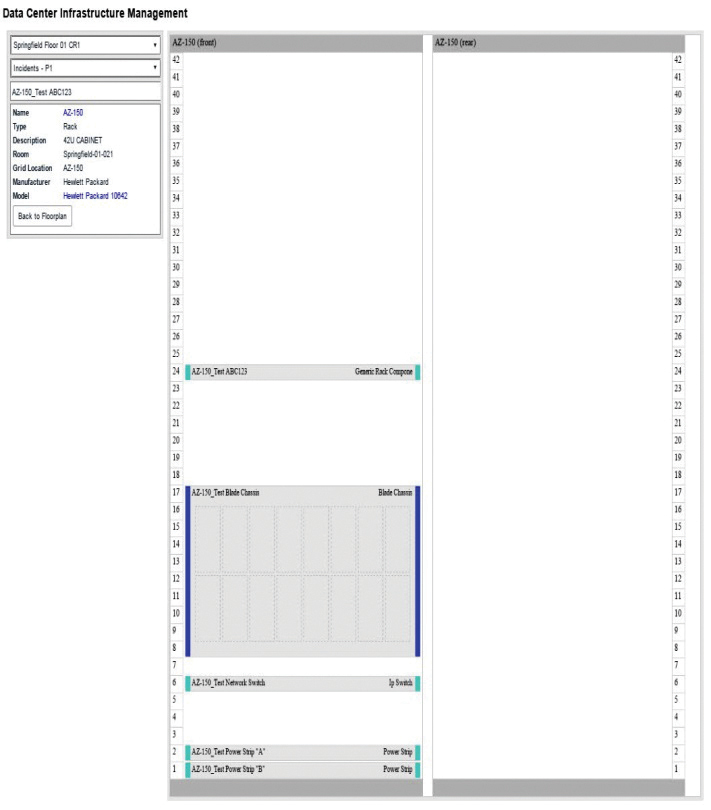
Figure 3. Front and rear rack elevation
Speaking of power management, our agile team was able to create an exact replica of our electrical panel schedules inside of the DCIM without losing any of the functionality we had in Excel. This included the ability to update current power draw for each individual breaker, redundant failover calculation, alarming, and relationship creation from PDU to breaker to floor-mount device.
Oh and by the way, iPad capability is here…. Technicians can update information as work is being performed on the floor, allowing Operations to know when a change request is actually in process and what progress has been made. And, 100% automation is in full effect here! Technicians can also bring up equipment procedures to follow along the way as these are tied to CIs using the Service Management Suite knowledge articles.
Our Service Management Suite is fully integrated with active directory, in that we can associate personnel with individual site locations that they manage. Self-service forms are also in place where users can add, modify, or delete any new vendor information for specific sites.
The Service Management Suite has already integrated with our Real Estate management tool to integrate remote floor plans, site contacts, and resource usage for each individual location. The ability to pull power consumption per device at remote sites is also standardized based on an actual determined estimate to assist with consolidation efforts.
The self-service items include automated life cycle forms that allow users to actively track equipment adds, modifications, and removals, while also providing the functionality to correlate CIs together in order to form relationships from generator to UPS to PDU to breaker to rack to power strip to rack-mount device (see Figure 4).
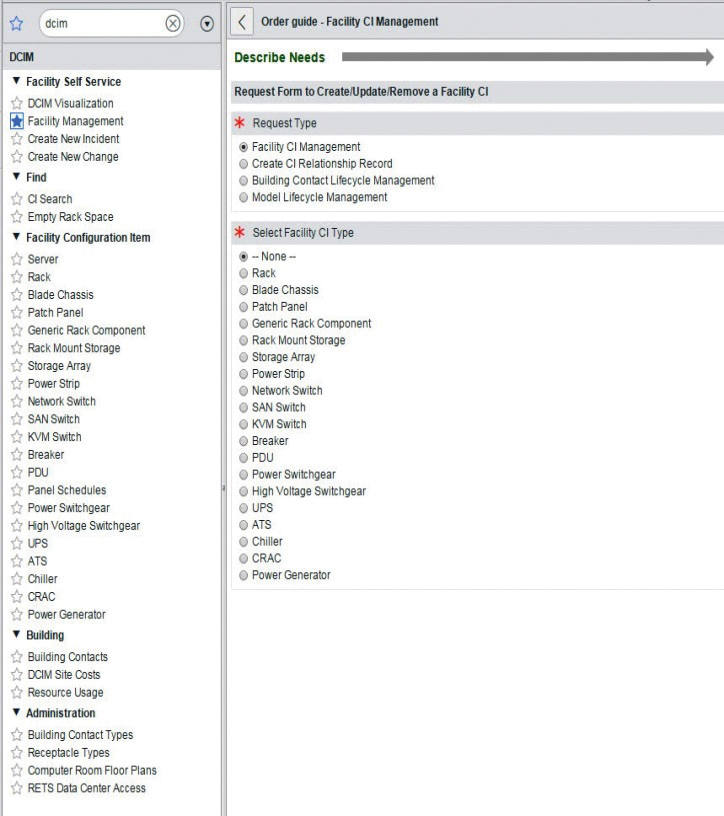
Figure 4. Self-service facility CI management form
Functionality for report creation on any CI and associated relationships has been implemented for all users. Need to determine where to place a server? There’s a report that can be run for that as well!
The streamlined processes allow users to maintain facility and hardware CIs with ease, and truly provides a 100% grasp on the activity occurring with data centers on a daily basis.
I am quite proud of the small, but powerful, team that went on this adventure with us. As the leader of this initiative, it was refreshing to see the idea start with a manager. He worked with a key developer to build workflows and from there turned DCIM on its head.
We pulled the hardware, network, and facility teams together with five amazing part-time developers for the “what if” brainstorm session and the enthusiasm continued to explode. It was truly amazing to observe this team. Within 30 days, we had a prototype that was shared with senior management and stakeholders who fully supported the effort and the rest is history!
It’s important to note, for RETS, we have a far superior tool set for a fraction of the cost of other DCIM tools. With it being embedded into our Service Management Suite,
we avoid additional maintenance, software, and vendor services costs… win, win, win!
Our DCIM is forever evolving in that we have so far surpassed the requirements we originally set that we thought, “Why stop now?” Continuing with our journey
will bring service impact reports and alarming, incorporating our existing power monitoring application, and building an automation system, which will enhance our ability to include remote location CIs managed by us. With all the advances we are able to make using our own system, I am looking forward to more productivity than ever before and more than we can imagine right now!
 Stephanie Singer joined Reed Elsevier, now known as RELX Group, in 1980 and has worked for Mead Data Central, LexisNexis, and Reed Elsevier–Technology Services during her career. She is currently the vice president of Global Data Center Services. In this role, she is responsible for global data center and server room facilities, networks, and cable plant infrastructure for the products and applications within these locations. She leads major infrastructure transformation efforts. Ms. Singer has led the data center facilities team since 1990, maintaining an excellent data center availability record throughout day-to-day operations and numerous lifecycle upgrades to the mechanical and electrical systems. She also led the construction and implementation of a strategic backup facility to provide in-house disaster recovery capability.
Stephanie Singer joined Reed Elsevier, now known as RELX Group, in 1980 and has worked for Mead Data Central, LexisNexis, and Reed Elsevier–Technology Services during her career. She is currently the vice president of Global Data Center Services. In this role, she is responsible for global data center and server room facilities, networks, and cable plant infrastructure for the products and applications within these locations. She leads major infrastructure transformation efforts. Ms. Singer has led the data center facilities team since 1990, maintaining an excellent data center availability record throughout day-to-day operations and numerous lifecycle upgrades to the mechanical and electrical systems. She also led the construction and implementation of a strategic backup facility to provide in-house disaster recovery capability.


 2020
2020


 UI @ 2020
UI @ 2020