 2019
2019Outages drive authorities and businesses to act
Big IT outages are occurring with growing regularity, many with severe consequences. Executives, industry authorities and governments alike are responding with more rules, calls for more transparency and a more formal approach to end-to-end, holistic resiliency.
Creeping criticality
IT outages and data center downtime can cause huge disruption. That is hardly news: veterans with long memories can remember severe IT problems caused by power outages, for example, back in the early 1990s.
Three decades on, the situation is vastly different. Almost every component and process in the entire IT supply chain has been engineered, re-engineered and architected for the better, with availability a prime design criterion. Failure avoidance and management, business continuity and data center resiliency has become a discipline, informed by proven approaches and supported by real-time data and a vast array of tools and systems.
But there is a paradox: The very success of IT, and of remotely delivered services, has created a critical dependency on IT in almost every business and for almost every business process. This dependency has radically increased in recent years. Many more outages — and there are more of them — have a more immediate, wider and bigger impact than in the past.
A particular issue that has affected many high-profile organizations, especially in industries such as air transport, finance and retail, is “asymmetric criticality” or “creeping criticality.” This refers to a situation in which the infrastructure and processes have not been upgraded or updated to reflect the growing criticality of the applications or business processes they support. Some of the infrastructure has a 15-year life cycle, a timeframe out of sync with the far faster pace of innovation and change in the IT market.
While the level of dependency on IT is growing, another big set of changes is still only partway through: the move to cloud and distributed IT architectures (which may or may not involve the public cloud). Cloud and distributed applications enable the move, in part or whole, to a more distributed approach to resiliency. This approach involves replicating data across availability zones (regional clusters of three or more data centers) and using a variety of software tools and approaches, distributed databases, decentralized traffic and workload management, data replication and disaster recovery as a service.
These approaches can be highly effective but bring two challenges. First are complexity and cost — these architectures are difficult to set up, manage and configure, even for a customer with no direct responsibility for the infrastructure (Uptime Institute data suggests that difficulties with IT and software contribute to ever more outages). And second, for most customers, is a loss of control, visibility and accountability. This loss of visibility is now troubling regulators, especially in the financial services sector, which now plan to exercise more oversight in the United States (US), Europe, the United Kingdom (UK) and elsewhere.
Will outages get worse?
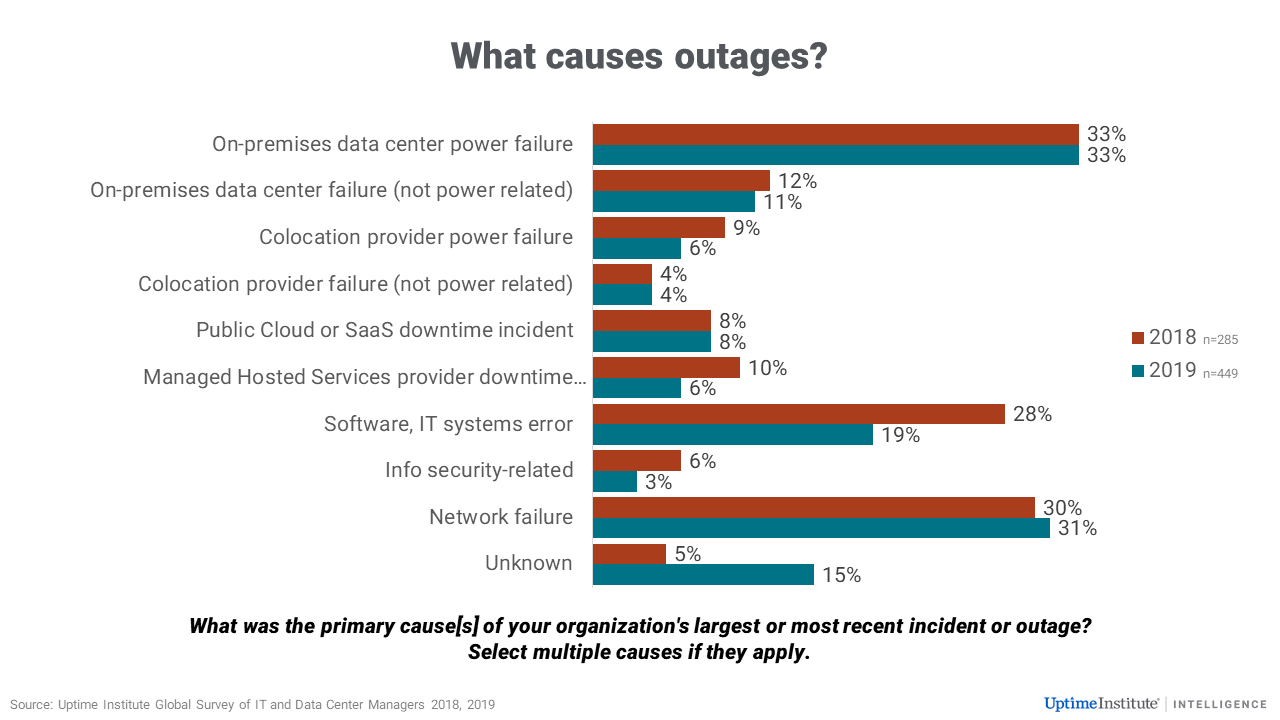
Are outages becoming more common or more damaging? The answer depends on the exact phrasing of the question: neither the number nor the severity of outages is increasing as a proportion of the level of IT services being deployed — in fact, reliability and availability is probably increasing, albeit perhaps not significantly.
But the absolute number of outages is clearly increasing. In both our 2018 and 2019 global annual surveys, half (almost exactly 50%) said their organization had a serious data center or IT outage in the past three years – and it is known that the number of data centers has risen significantly during this time. Our data also shows the impact of these outages is serious or severe in almost 20% of cases, with many industry sectors, including public cloud and colocation, suffering problems.
What next?
The industry is now at an inflection point; whatever the overall rate of outages, the impact of outages at all levels has become more public, has more consequential effects, and is therefore more costly. This trend will continue for several years, as networks, IT and cloud services take time to mature and evolve to meet the heavy availability demands put upon them. More high-profile outages can be expected, and more sectors and governments will start examining the nature of critical infrastructure.

This has already started in earnest: In the UK, the Bank of England is investigating large banks’ reliance on cloud as part of a broader risk-reduction initiative for financial digital services. The European Banking Authority specifically states that an outsourcer/cloud operator must allow site inspections of data centers. And in the US, the Federal Reserve has conducted a formal examination of at least one Amazon Web Services (AWS) data center, in Virginia, with a focus on its infrastructure resiliency and backup systems. More site visits are expected.
Authorities in the Netherlands, Sweden and the US have also been examining the resiliency of 911 services after a series of failures. And in the US, the General Accounting Office published an analysis to determine what could be done about the impact and frequency of IT outages at airlines. Meanwhile, data centers themselves will continue to be the most resilient and mature component (and with Uptime Institute certification, can be shown to be designed and operated for resiliency). There are very few signs that any sector of the market (enterprise, colocation or cloud) plans on downgrading physical infrastructure redundancy.
As a result of the high impact of outages, a much greater focus on resiliency can be expected, with best practices and management, investment, technical architectures, transparency and reporting, and legal responsibility all under discussion.
The full report Ten data center industry trends in 2020 is available to members of the Uptime Institute Network here.



 UI @ 2021
UI @ 2021



 2019
2019