 2019
2019Data center AI: Start with the end in mind
An artificial intelligence (AI) strategy for data center management and operation requires more than just data and some very smart humans. Selecting specific use cases and understanding the types of data that influence AI outcomes — and then validating those outcomes — will be key if the needs of the business are to be met.
By focusing on specific use cases, early successes can then be scaled, and further value can be extracted incrementally. Managers don’t need to be AI experts, but Uptime Institute does recommend that they understand the fundamental depth and breadth of the AI being applied. Doing so means they can better determine how much data is required and how the AI will be using the data, which will be critical when validating results and recommendations.
In a recent report written by Uptime Institute Intelligence entitled “Very smart data centers: How artificial intelligence will power operational decisions” on the subject of AI in data centers, should provide a better understanding of what is required.
As a first step, let’s address a few points about AI. First, what is the difference between algorithms and models? AI marketers can use these terms to mean the same thing, although they are not.
An algorithm is a sequence of mathematical steps or computational instructions. It is an automated instruction set. An algorithm can be a single instruction or a sequence of instructions — its complexity depends on how simple or complex each individual instruction is and/or the sheer number of instructions that the algorithm needs to execute.
In AI, a model refers to a mathematical model that is able to process data and provide the expected response to or outcome of that data. For example, if an algorithm is applied to a data set, the outcome would be the model. So, the model is the outcome of one or many algorithms. A model changes if the data fed into the algorithm changes, or if the same data is fed through a different algorithm.
Another very important distinction is between the two main types of AI techniques being used in data centers today: machine learning and deep learning.
There are three main types of machine learning techniques:
- Supervised learning: Humans supply a model and training data. Algorithms take the training data and fine-tune the model so the inputs and outputs/responses are more closely aligned. As more data is added over time, the algorithms further improve the model and can make reasonable predictions for responses to new data. Supervised machine learning is most commonly used in data centers and other industries.
- Unsupervised learning: Algorithms find patterns or intrinsic structures in unlabeled data. In some scenarios, unsupervised machine learning techniques are combined with supervised ones. In effect, the output of unsupervised machine learning can become the training data for supervised machine learning.
- Reinforcement learning: Humans supply a model and unlabeled data. When an algorithm determines an optimal outcome for the data, it is reinforced by a positive mathematical “reward.” (An open-source reinforcement learning model from Google is appropriately called Dopamine.) By providing feedback, it learns through different variations. Of these, reinforcement learning is the newest machine learning technique.
Deep learning, a subset of machine learning, uses multiple layers of artificial neural networks to build algorithms, based on vast data, that find an optimal way to make decisions or perform tasks on their own. Humans supply training data and algorithms, and the computer breaks down these inputs into a hierarchy of very simple concepts. Each concept becomes a mathematical node on the neutral network. Instead of using machine learning models from humans, deep learning uses the training data like a neural network, which works like a decision tree. It builds new models from its own analysis of the training data.
Which technique is best for which use case? It depends on the quality and sophistication of the algorithm, as well as the model and data being used. If all these things are equal, however, there are certain techniques that are particularly well-suited to certain use cases.
Some say deep learning can find greater levels of inefficiencies because it is unfettered by known models. On the other hand, supervised machine learning is more transparent (making it easier for domain-expert humans to validate results) and, arguably, quicker to automate.
It can vary but below are some use cases that can be well-suited to different types of machine learning and for deep learning.
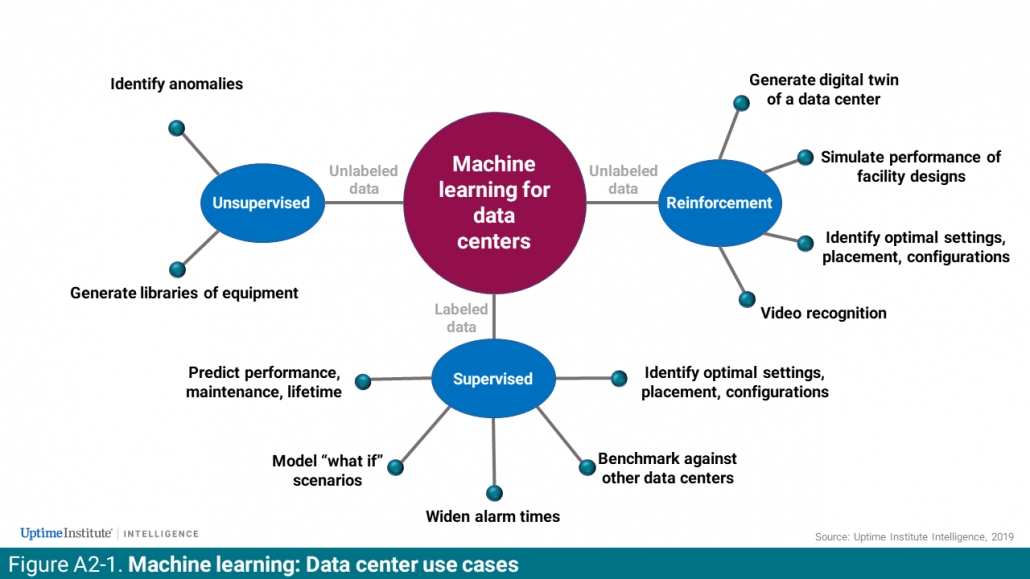
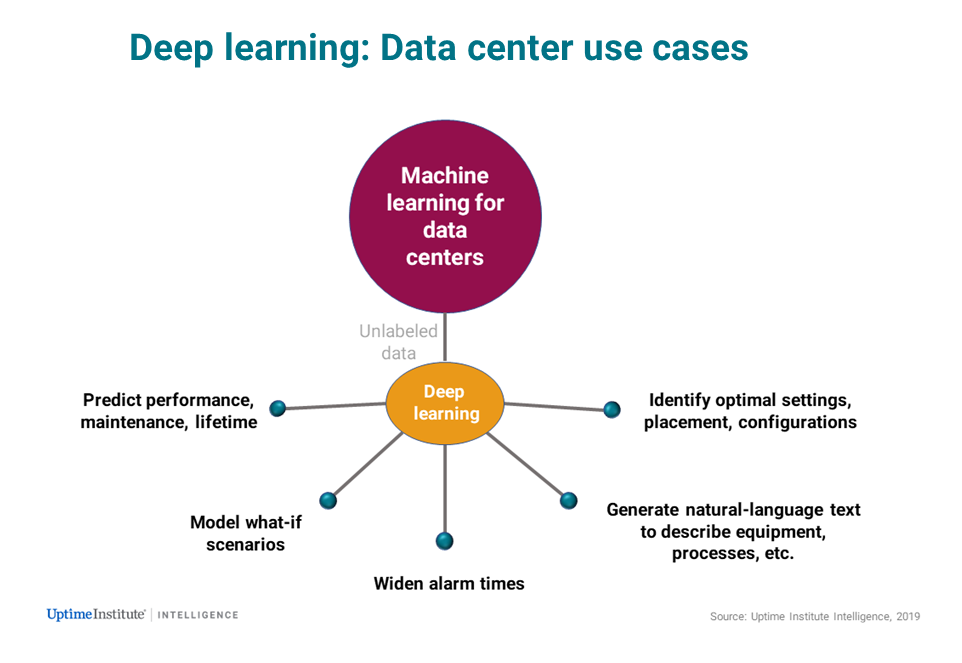
It is still early days, but it is likely that certain techniques will dominate specific use cases over time.
At a minimum, operators should understand the fundamental level of the depth and breadth of the AI being applied. Ask the supplier to show the data points in the model and the relationship between those items — in other words, how the AI is using the data to make recommendations for action. And, of course, it is always important to track the results when actions are taken (by a human operator).
The full report Very smart data centers: How artificial intelligence will power operational decisions is available to members of the Uptime Institute Network community. For more information about membership, click here.

 2019
2019






 2019
2019