
Data Center Outages, Incidents, and Industry Transparency
The lack of transparency can be seen as a root cause of outages and incidents
By Jason Weckworth
I recently began a keynote speech at Uptime Institute Symposium 2013 by making a bold statement. As data center operators, we simply don’t share enough of our critical facilities incidents with each other. Yet Uptime Institute maintains an entire membership organization called the Uptime Institute Network that is dedicated to providing owners and operators the ability to share experiences and best practices by facilitating a rich information nexus exchange between members and the Uptime Institute.
Why isn’t every major data center provider already a member of this Network? Why don’t we share more experiences with each other? Why are we reluctant to share details of our incidents? Of course, we love to talk about each other’s incidents as though our competitors were hit with a plague while we remain immune from any potential for disaster. Our industry remains very secretive about sharing incidents and details of incidents, yet we can all learn so much from each other!
I suppose we’re reluctant to share details with each other because of fear that the information could be used against us in future sales opportunities, but I’ve learned that customers and prospects alike expect data center incidents. Clients are far less concerned about the fact that we will have incidents than about how we actually manage them. So let’s raise the bar as operators. Let’s acknowledge the fact that we need to be better as an industry. We are an insurance policy for every type of critical IT business. None of us can afford to take our customers off-line… period. And when someone does, it hurts our entire industry.
Incidents Every Day
An incident does not mean a data center outage. These terms are often confused, misinterpreted or exaggerated. An outage represents a complete loss of power or cooling to a customer’s rack or power supply. It means loss of both cords, if dual fed, or loss of single cord, if utilizing a transfer switch either upstream or at the rack level.
Equipment and systems will break, period. Expect it. Some will be minor like a faulty vibration switch. Others will be major like an underground cable fault that takes out an entire megawatt of live UPS load (which happened to us). Neither of these types of incidents are an outage at the rack level, yet either of them could result in one if not mitigated properly.
Data Center Risk
Do not ask whether any particular data center has failures. Ask what they do when they have a failure. There is a lot of public data available on the causes of data center outages and incidents, but I particularly like a data set published by Emerson (see Figure 1) because it highlights the fact that most data center incidents are caused by human and mechanical failures, not weather or natural disasters. Uptime Institute Network data provide similar results. This means that, as operators, we play a major role with facility management.
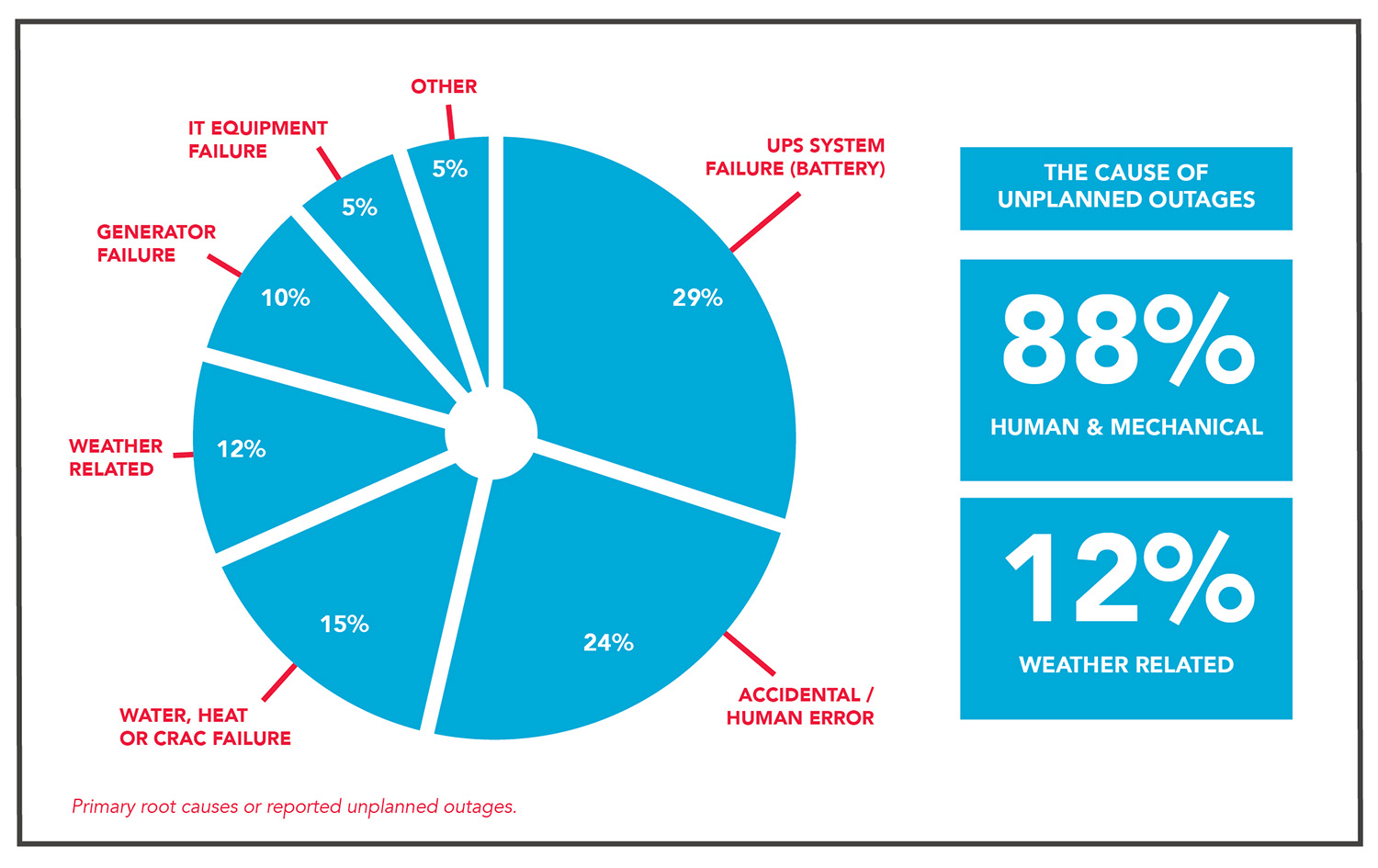
Figure 1. Data provided by Emerson shows that human and mechanical failures cause the vast majority of unplanned outages in data centers.
I have been involved with every data center incident at RagingWire since its opening in 2001. By the end of this year, that will equate to almost 100 megawatt (MW) of generating capacity and 50 MW of critical IT UPS power. I must admit that data center incidents are not pleasant experiences. But learning from them makes us better as a company, and sharing the lessons make us better as an industry.
In 2006, RagingWire experienced one particularly bad incident caused by a defective main breaker that resulted in a complete outage. I distinctly recall sitting in front of the Board of Directors and Executives at 2:00 AM trying to explain what we knew up to that point in time. But we didn’t yet have a root-cause analysis. One of the chief executives looked at me across the table and said, “Jason, we love you and understand the incredible efforts that you and your teams have put forth. You haven’t slept in two days. We know we are stable at the current time, but we don’t yet have an answer for the root cause of the failure, and we have enterprise Fortune 500 companies that are relying on us to give them an answer immediately as our entire business is at risk. So make no mistake. There will be a fall guy, and it’s going to be you if we don’t have the answer to prove this will never happen again. You have four hours, or you and all your engineers are fired!” Fortunately, I’m still at RagingWire, so the story ended well. We used the experience to completely modify our design from N+1 to 2N+2 infrastructure, so that we would never again experience this type of failure. But, I never forgot this idea of our natural tendency to assign blame. It’s hard to fight this cultural phenomenon because there is so much at stake for our operators, but I believe that it is far more important to look beyond blame. Frankly, it doesn’t matter in the immediate aftermath of an incident. Priority #1 is to get operations back to 100%. How does a data center recover? How do you know when your business will be fully protected?

Data centers fail. It is important to understand the root cause and to make sure to fix the vulnerability.
Life Cycle of an Outage
Now I don’t mean to offend anyone, but I do make fun of the communication life cycle that we all go through with every major incident. Of course, we know this is a very serious business, and we live and breathe data center 24 hours per day. But sometimes we need to take a break from the insanity and realize that we’re all in this together. So, here is what I consider to be the communication life cycle of our customers. And often, it’s the same response we see from the Executive Teams!
Stage 1: SURPRISE. Are you kidding? This just happened at your data center? I didn’t think this could happen here! Are my servers down?!?
Stage 2: FEAR. What is really happening? Is it worse than you are telling me? What else is at risk? What aren’t you telling me? Are you going to experience a cascading failure and take down my entire environment?
Stage 3: ANGER. How could this possibly happen? I pay you thousands (or millions) of dollars every month to ensure my uptime! You’re going to pay for this! This is a violation of my SLA.
Stage 4: INTERROGATION. Why did this happen? I want to know every detail. You need to come to my office to explain what happened, lessons learned and why it will never happen again! Where is your incident report? Who did what? And why did it take you so long to notify my staff? Why didn’t you call me directly, before I heard about it from someone else?
Of course, the “not so funny” part of this life cycle is that in reality, all of these reactions are valid. We need to be prepared to address every response, and we truly need to become better operators with every incident.
Operational Priorities
After 12 years of industry growth, many phased expansions into existing infrastructure and major design modifications to increase reliability, I have found that the majority of my time and effort always remains our risk management of the data center as it relates to uptime. Data centers are not created equal. There are many different design strategies and acceptable levels of risk, such as N+1, 2N, 2N+2, etc. However, our common goal as operators is to mitigate risk, address incidents quickly and thoroughly, and return the facility to its original, normal condition, with full redundancy.
The following eight areas represent what I consider to be the most important factors contributing to a data center’s ability to deliver a very high level of operational excellence:
• Staffing. Experience matters. I love to hire Navy nuclear technicians, because they are so disciplined. But, my favorite interview question more than any other, is to ask potential candidates about the incidents they have experienced in the data center. I want people who have lived through the fire. I want to know how they acted under pressure, what went wrong and what surprises they faced. The more difficult the incidents were, the more I appreciate them! There is no substitute for experience, and there is no way to gain experience other than one incident at a time. I also believe that it’s important to have 24×7 technical staff at the data center. Even with sophisticated control systems, there are many, many instances that require human intervention and on-site analysis/decision making, usually within minutes.
• Training. Do you train by process or by trial? It’s important to do both. How do you practice casualty control drills? I like to involve the entire operations staff when we commission a new phase, because we can throw in unexpected failures and test the staff without live load. I also like to thoroughly review every incident with the entire staff during a weekly training meeting, so that they can learn from real-world experiences. Training assessment should be part of every technician’s annual review, with merit given for mastering various areas of the data center operation.
• Resources. I personally prefer in-house expertise and first-level response, but only because design and construction are core in-house disciplines with self-performed labor. During a recent underground cable fault that lost an entire one megawatt UPS feeder, all the loads transferred to alternate UPS sources under a distributed redundancy topology, but the fault created a heat sink with two additional megawatts at risk that we couldn’t cool. With a literal time bomb on our hands and wire temperatures approaching 200°F, we engaged almost 40 in-house electricians to work 24-hours straight in order to run a new overhead feeder and commission it in order to vacate the underground duct bank and cool the environment.
Of course, staffing doesn’t need to be in-house. But it’s important to have immediate access and key contacts at any moment’s notice. This can be suppliers, service contractors or engineers. I have particularly found that key equipment factory engineers have a wealth of knowledge–if you can gain access to them during an incident.
• Incident Reporting. Incident reporting should be the lifeblood of every data center operator. What kind of visibility do they have? Are they reviewed and approved by Operations, Engineering and Executive staff? I personally review, comment on and approve every incident within the data center. Do you share your incident reports with customers? Some operators may prefer to provide a Summary Report, but we should always be willing to share the entire report to any customer that requests one. Another important detail is follow-up. We tend to be very good at documenting initial incidents, but we struggled with all the follow-up as it related to engineering, vendor support and further testing. If your technicians are always putting out fires, it’s difficult to stay focused on the follow-up. For this reason, we initiated a separated SaaS application called FrontRange that allows us to assign tasks with timed escalation for every follow-up item.
• Escalation. Every incident management protocol needs clear escalation channels. What is critical vs. minor? How detailed is your notification and escalation policy? Is re-training frequent due to non-compliance with escalation procedures? Do you have an escalation process that automatically includes engineering staff? Do you include key vendors within your internal escalation process? Do you have automatic dialing so that you can reach multiple sources within minutes with bridge lines? Do you have an incident manager separate from a communication manager? How fast can your staff mobilize, and do they know when to escalate? Is everyone trained regularly?
• Communication. What is your protocol for controlled dissemination of information? Do you have a dedicated communications manager? This may be part of your NOC staff or a dedicated operations staff member with technical knowledge. How will clients be notified during an incident? Do you allow clients direct visibility to equipment status? Do you set up bridge calls with automatic dialers to affected customers for direct communication during events? Do you have a timed protocol to deliver incident reports with 24 or 48 hours? Do you have a communication protocol for your executive team or account managers so they can also contact your customers or at least have knowledge of what is happening? Sometimes it is just as important to communicate with your internal staff as it is your customers.
• Back-up Plans. Can you provide examples of when the unexpected happened? What are your contingency plans? The data center design has back-up redundancy, but what about operational back up with staffing, suppliers, engineering resources and spare parts? You need basic support like food, clothes and sleep. We’ve experienced needs to keep qualified supervisors or directors on-site just to help with MOP-writing or operational commissioning after a break-fix, yet often these staff members can be completely exhausted.
• Top 10 Incidents. One of the most challenging sales support meetings I ever attended was for a Fortune 100 company. The CIO explained that they had never used colocation outsourcing in the past, and they were particularly concerned with our ability to handle incidents efficiently and communicate clearly to their teams exactly what was happening on a real-time basis. Of course, I am proud of our process and procedures around incident management, and I quickly described many of the ideas that I have touched on within this article. Then he surprised me. He asked me if I could name the Top 10 incidents we’ve had in our data center, what the root causes were, and what engineering changes or process changes we made as a result. I quickly responded by saying “yes, I am pretty sure I know most of these.” So he stated that we would like to know on the spot, because that knowledge off the top of my head from an executive staff member would clearly demonstrate that these issues are important and top of mind to everyone in operations. We spent the next 2 hours talking through each incident as best as I could remember. I must admit that although I named ten incidents, they probably weren’t the top ten over the past ten years. And it was an incredibly stressful meeting for me! But it was an awesome teaching moment for me and my staff.
Conclusion: Our Industry Can Be Better
We all need to know the incidents that shape our data center. We need to qualify improvements to the data center through our incident management process, and we need to be able to share these experiences with both our staff and our customers and with other operators.

Placing blame takes a back seat to identifying root causes and preventing recurrence.
I encourage every operator or data center provider to join the Uptime Institute Network. This is not a sales or vendor organization. It’s an operator’s organization with a commitment from all members to protect information of other members. Here are just a few of the benefits of the Network:
• Learning experiences from over 5,000 collected incidents from members
• Abnormal incident trending that allow members to focus resources on areas most likely to cause downtime
• “Flash” reports or early warning bulletins that could impact other member’s facilities
• Cost savings resulting from validation of equipment purchases or alternative sourcing options
• Tours of Network member data centers with the opportunity to apply ideas on best practices or improvements
• Access to member presentations from technical conferences

Sharing information can help find new ways of preventing old problems from causing issues.
I am also hoping to challenge our industry. If we can become more transparent as operators within a common industry, we will all become better. Our designs and technology may be different, but we still share a very common thread. Our common goal remains the confidence of our industry through uptime of our facilities.
 Jason Weckworth is senior vice president and COO, RagingWire Data Centers. He has executive responsibility for critical facilities design and development, critical facilities operations, construction, quality assurance, client services, infrastructure service delivery and physical security. Mr. Weckworth brings 25 years of data center operations and construction expertise to the data center industry. Previous to joining RagingWire, he was owner and CEO of Weckworth Construction Company, which focused on the design and construction of highly reliable data center infrastructure by self-performing all electrical work for operational best practices. Mr. Weckworth holds a bachelor’s degree in Business Administration from the California State University, Sacramento.
Jason Weckworth is senior vice president and COO, RagingWire Data Centers. He has executive responsibility for critical facilities design and development, critical facilities operations, construction, quality assurance, client services, infrastructure service delivery and physical security. Mr. Weckworth brings 25 years of data center operations and construction expertise to the data center industry. Previous to joining RagingWire, he was owner and CEO of Weckworth Construction Company, which focused on the design and construction of highly reliable data center infrastructure by self-performing all electrical work for operational best practices. Mr. Weckworth holds a bachelor’s degree in Business Administration from the California State University, Sacramento.




 UI @ 2021
UI @ 2021


 UI @ 2021
UI @ 2021