
Failure Doesn’t Keep Business Hours: 24×7 Coverage
A statistical justification for 24×7 coverage
By Richard Van Loo
As a result of performing numerous operational assessments at data centers around the world, Uptime Institute has observed that staffing levels at data centers vary greatly from site to site. This observation is discouraging, but not surprising, because while staffing is an important function for data centers attempting to maintain operational excellence, many factors influence an organization’s decision on appropriate staffing levels.
Factors that can affect overall staffing numbers include the complexity of the data center, the level of IT turnover, the number of support activity hours required, the number of vendors contracted to support operations, and business objectives for availability. Cost is also a concern because each staff member represents a direct cost. Because of these numerous factors, data center staffing levels must be constantly reviewed in an attempt to achieve effective data center support at a reasonable cost.
Uptime Institute is often asked, “What is the proper staffing level for my data center.” Unfortunately, there is no quick answer that works for every data center since proper staffing depends on a number of variables.
The time required to perform maintenance tasks and provide shift coverage support are two basic variables. Staffing for maintenance hours requirements is relatively fixed, but affected by which activities are performed by data center personnel and which are performed by vendors. Shift coverage support is defined as staffing for data center monitoring and rounds and for responding to any incidents or events. Staffing levels to support shift coverage can be provided in a number of different ways. Each method of providing shift coverage has potential impacts on operations depending on how that that coverage is focused.
TRENDS IN SHIFT COVERAGE
The primary purpose of having qualified personnel on site is to mitigate the risk of an outage caused by abnormal incidents or events, either by preventing the incident or containing and isolating the incident or event and keeping it from spreading or impacting other systems. Many data centers still support data shift presence with a team of qualified electricians, mechanics, and other technicians who provide 24 x 7 shift coverage. Remote monitoring technology, designs that incorporate redundancy, campus data center environments, the desire to balance costs, and other practices can lead organizations to deploy personnel differently.
Managing shift presence without having qualified personnel on site at all times can elevate risks due to delayed response to abnormal incidents. Ultimately, the acceptable level of risk must be a company decision.
Other shift presence models include:
• Training security personnel to respond to alarms and execute an escalation procedure
• Monitoring the data center through a local or regional building monitoring system (BMS) and having technicians on call
• Having personnel on site during normal business hours and on call during nights and weekends
• Operating multiple data centers as a campus or portfolio so that a team supports multiple data centers without necessarily being on site at each individual data center at a given time
These and other models have to be individually assessed for effectiveness. To assess the effectiveness of any shift presence model, the data center must determine the potential risks of incidents to the operations of the data center and the impact on the business.
For the last 20 years, Uptime Institute has built the Abnormal Incident Reports (AIRs) database using information reported by Uptime Institute Network members. Uptime Institute analyzes the data annually and reports its findings to Network members. The AIRs database provides interesting insights relating to staffing concerns and effective staffing models.
INCIDENTS OCCUR OUTSIDE BUSINESS HOURS
In 2013, a slight majority of incidents (out of 277 total incidents) occurred during normal business hours. However, 44% of incidents happened between midnight and 8:00 a.m., which underscores the potential need for 24 x 7 coverage (see Figure 1).
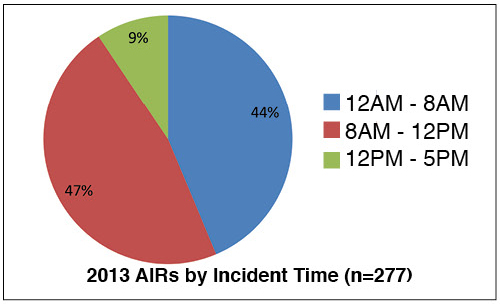
Figure 1. Approximately half the AIRs that occurred in 2013 took place occurred between 8 a.m. and 12 p.m., the other half between 12 a.m. and 8 a.m.
Similarly, incidents can happen at any time of the year. As a result, focusing shift presence activities toward a certain time of year over others would not be productive. Incident occurrence is pretty evenly spread out over the year.
Figure 2 details the day of the week when incidents occurred. The chart shows that incidents occur on nearly an equal basis every day of the week, which suggests that shift presence requirement levels should be the same every day of the week. To do otherwise would leave shifts with little or no shift presence to mitigate risks. This is an important finding because some data centers focus their shift presence support Monday through Friday and leave weekends to more remote monitoring (see Figure 2).
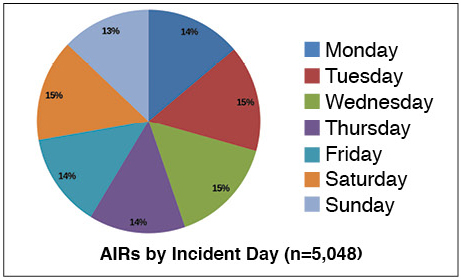
Figure 2. Data center staff must be ready every day of the week.
INCIDENTS BY INDUSTRY
Figure 3 further breaks down the incidents by industry and shows no significant difference in those trends between industries. The chart does show that the financial services industry reported far more incidents than other industries, but that number reflects the makeup of the sample more than anything.
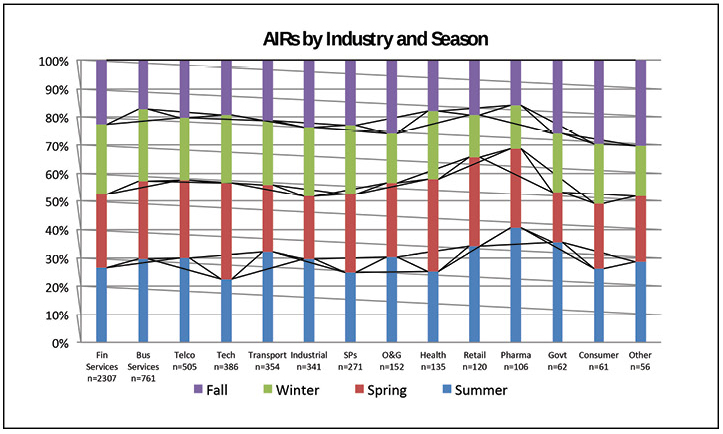
Figure 3. Incidents in data centers take place all year round.
INCIDENT BREAKDOWNS
Knowing when incidents occur does little to say what personnel should be on site. Knowing what kinds of incidents occur most often will help shape the composition of the on-site staff, as will knowing how incidents are most often identified. Figure 4 shows that electrical systems experience the most incidents, followed by mechanical systems. By contrast, critical IT load causes relatively few incidents.
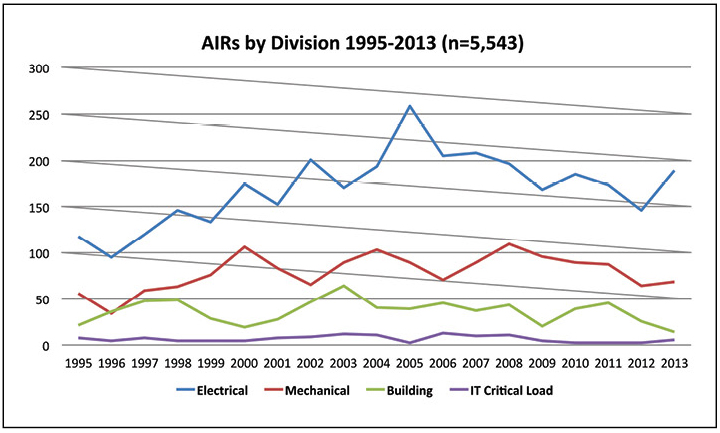
Figure 4. More than half the AIRs reported in 2013 involved the electrical system.
As a result, it would seem to make sense that shift presence teams should have sufficient electrical experience to respond to the most common incidents. The shift presence team must also respond to other types of incidents, but cross training electrical staff in mechanical and building systems might provide sufficient coverage. And, on-call personnel might cover the relatively rare IT-related incidents.
The AIRs database also sheds some light on how incidents are discovered. Figure 5 suggests that over half of all incidents discovered in 2013 were from alarms and more than 40% of incidents are discovered by technicians on site, totaling about 95% of incidents. The biggest change over the years covered by the chart is a slow growth of incidents discovered by alarm.
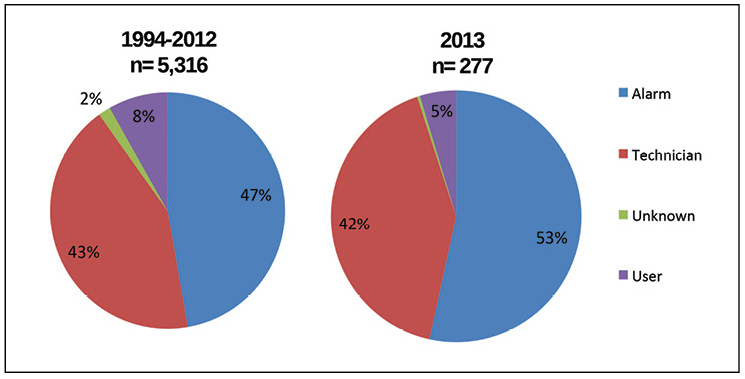
Figure 5. Alarms are now the source for most AIRs; however, availability failures are more likely to be found by technicians.
Alarms, however, cannot respond to or mitigate incidents. Uptime Institute has witnessed a number of methods for saving a data center from going down and reducing the impact of a data center incident. These methods require having personnel to respond to the incident, building redundancy into critical systems, and strong predictive maintenance programs to forecast potential failures before they occur. Figure 6 breaks down how often each of these methods produced actual saves.
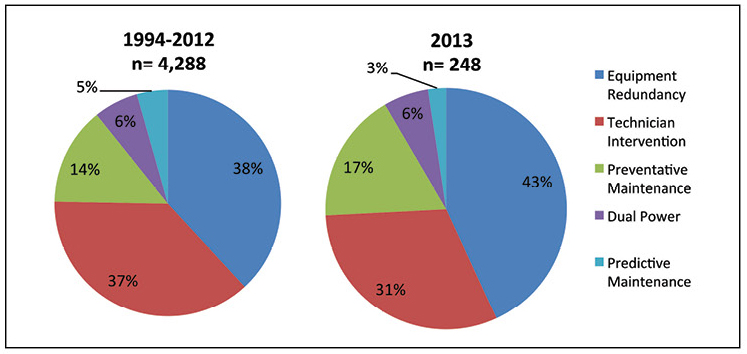
Figure 6. Equipment redundancy was responsible for more saves in 2013 than in previous years.
The chart also appears to suggest that in recent years, equipment redundancy and predictive maintenance are producing more saves and technicians fewer. There are several possible explanations for this finding, including more robust systems, greater use of predictive maintenance, and budget cuts that reduce staffing or move it off site.
FAILURES
The data show that all the availability failures in 2013 were caused by electrical system incidents. A majority of the failures occurred because maintenance procedures were not followed. This finding underscores the importance of having proper procedures and well trained staff, and ensuring that vendors are familiar with the site and procedures.
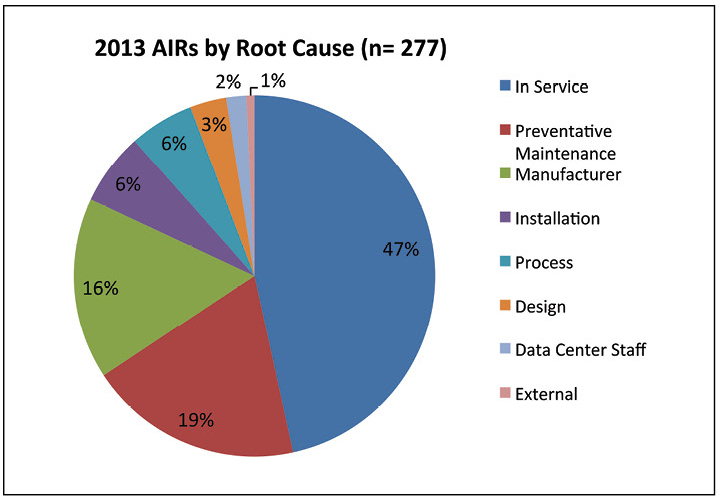
Figure 7. Almost half the AIRs reported in 2013 were In Service.
Figure 7 further explores the causes of incidents in 2013. Roughly half the incidents were described as “In Service,” which is defined as inadequate maintenance, equipment adjustment, operated to failure, or no root cause found. The incidents attributed to preventive maintenance actually refer to preventive maintenance that was performed improperly. Data center staff caused just 2% of incidents, showing that the interface of personnel and equipment is not a main cause of incidents and outages.
SUMMARY
The increasing sophistication of data center infrastructure management (DCIM), building management systems (BMS), and building automation systems (BAS) is increasing the question of whether staffing can be reduced at data centers. The advances in these systems are great and can enhance the operations of your data center; however, as the AIRs data shows, mitigation of incidents often requires on-site personnel. This is why it is still a prescriptive behavior for Tier III and Tier IV Operational Sustainability Certified data centers to have qualified full time equivalent (FTE) personnel on site at all times. The driving purpose is to provide quick response time to mitigate any incidents and events. The data show that there is no pattern as to when incidents occur. Their occurrence is pretty well spread across all hours of the day and all days of the week. Watching as data centers continue to evolve with increased remote access and more redundancy built in, will show if the trends continue in their current path. As with any data center operations program the fundamental objective is risk avoidance. Each data center is unique with its own set of inherent risks. Shift presence is just one factor, but a pretty important one; a decision on how many to staff, for each shift, and with what qualifications, can have major impact on risk avoidance and continued data center availability. Choose wisely.

Rich Van Loo
Rich Van Loo is Vice President, Operations for Uptime Institute. He performs Uptime Institute Professional Services audits and Operational Sustainability Certifications. He also serves as an instructor for the Accredited Tier Specialist course.
Mr. Van Loo’s work in critical facilities includes responsibilities ranging from projects manager of a major facility infrastructure service contract for a data center, space planning for the design/construct for several data center modifications, and facilities IT support. As a contractor for the Department of Defense, Mr. Van Loo provided planning, design, construction, operation, and maintenance of worldwide mission critical data center facilities. Mr. Van Loo’s 27-year career includes 11 years as a facility engineer and 15 years as a data center manager.




 UI @ 2021
UI @ 2021

 2020
2020