
Data-Driven Approach to Reduce Failures
Operations teams use the Uptime Institute Network’s Abnormal Incident Reports (AIRs) database to enrich site knowledge, enhance preventative maintenance, and improve preparedness
By Ron Davis
The AIRs system is one of the most valuable resources available to Uptime Institute Network members. It comprises more than 5,000 data center incidents and errors spanning two decades of site operations. Using AIRs to leverage the collective learning experiences of many of the world’s leading data center organizations helps Network members improve their operating effectiveness and risk management.
A quick search of the database, using various parameters or keywords, turns up invaluable documentation on a broad range of facility and equipment topics. The results can support evidence-based decision making and operational planning to guide process improvement, identify gaps in documentation and procedures, refine training and drills, benchmark against successful organizations, inform purchasing decisions, fine-tune preventive maintenance (PM) programs to minimize failure risk, help maximize uptime, and support financial planning.
THE VALUE OF AIRs OPERATIONS
The philosopher, essayist, poet, and novelist George Santayana wrote, “Those who cannot remember the past are doomed to repeat it.” Using records of past data center incidents, errors, and outages can help inform operational practices to help prevent future incidents.
All Network member organizations participate in the AIRs program, ensuring a broad sample of incident information from data center organizations representing diverse sizes, business sectors, and geography. It comprises more than 5,000 data center incidents and errors spanning two decades of site operations. Using AIRs to leverage the collective learning experiences of many of the world’s leading data center organizations helps Network members improve their operating effectiveness and risk management. The database contains data resulting from data center facility infrastructure incidents and outages for a period beginning in 1994 and continuing through the present. This volume of incident data allows for meaningful and extremely valuable analysis of trends and emerging patterns. Annually, Uptime Institute presents aggregated results and analysis of the AIRs database, spotlighting issues from the year and both current and historical trends.
Going beyond the annual aggregate trend reporting there is also significant insight to be gained from looking at individual incidents. Detailed incident information is particularly relevant to front-line operators, helping to inform key facility activities including:
• Operational documentation creation or improvement
• Planned maintenance process development or improvement
• Training
• PM
• Purchasing
• Effective practices, failure analysis, lessons learned
AIRs reporting is confidential and subject to a non-disclosure agreement (NDA), but the following hypothetical case study illustrates how AIRs information can be applied to improve an organization’s operations and effectiveness.
USING THE AIRs DATA IN OPERATIONS: CASE STUDY
A hypothetical “Site X” is installing a popular model of uninterruptible power supply (UPS) modules.
The facility engineer decides to research equipment incident reports for any useful information to help the site prepare for a smooth installation and operation of these critical units.
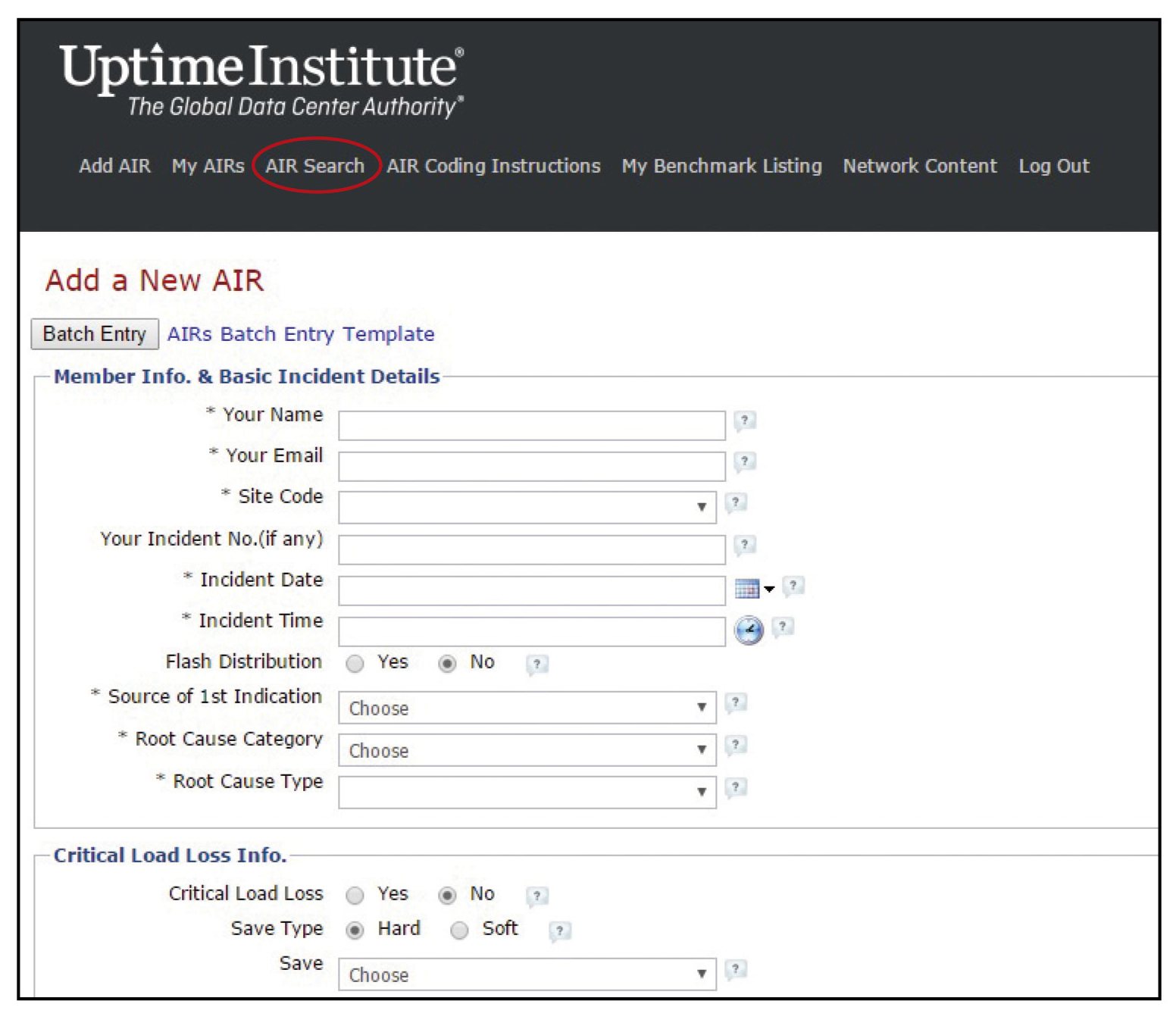
Figure 1. The page where members regularly go to submit an AIR. The circled link takes you directly to the “AIR Search” page.
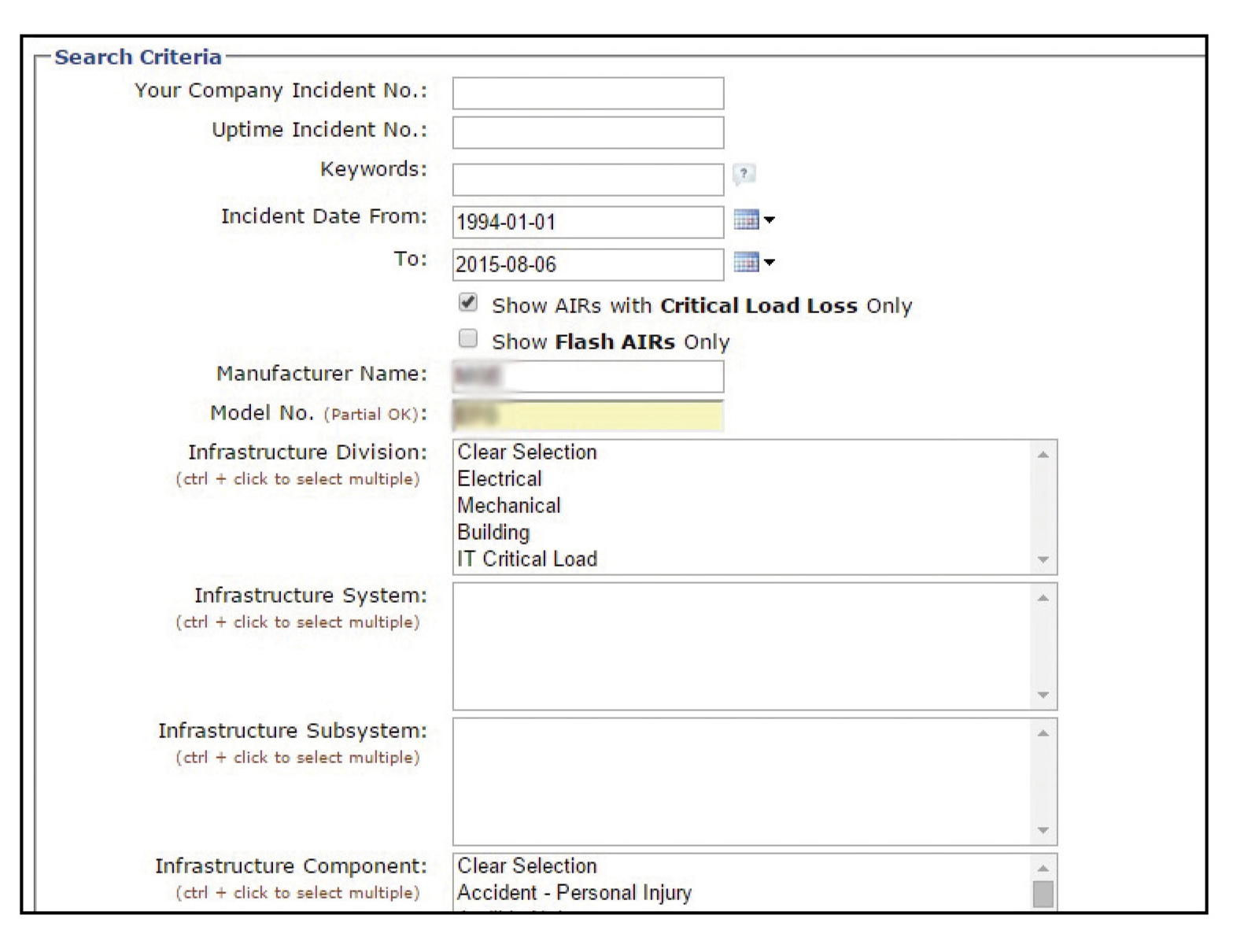
Figure 2. The AIR Search page is the starting point for Abnormal Incident research. The page is structured to facilitate broad searches but includes user friendly filters that permit efficient and effective narrowing of the desired search results.
The facility engineer searches the AIRs database using specific filter criteria (see Figures 1 and 2), looking for any incidents within the last 10 years (2005-2015) involving the specific manufacturer and model where there was a critical load loss. The database search returns seven incidents meeting those criteria (see Figure 3).
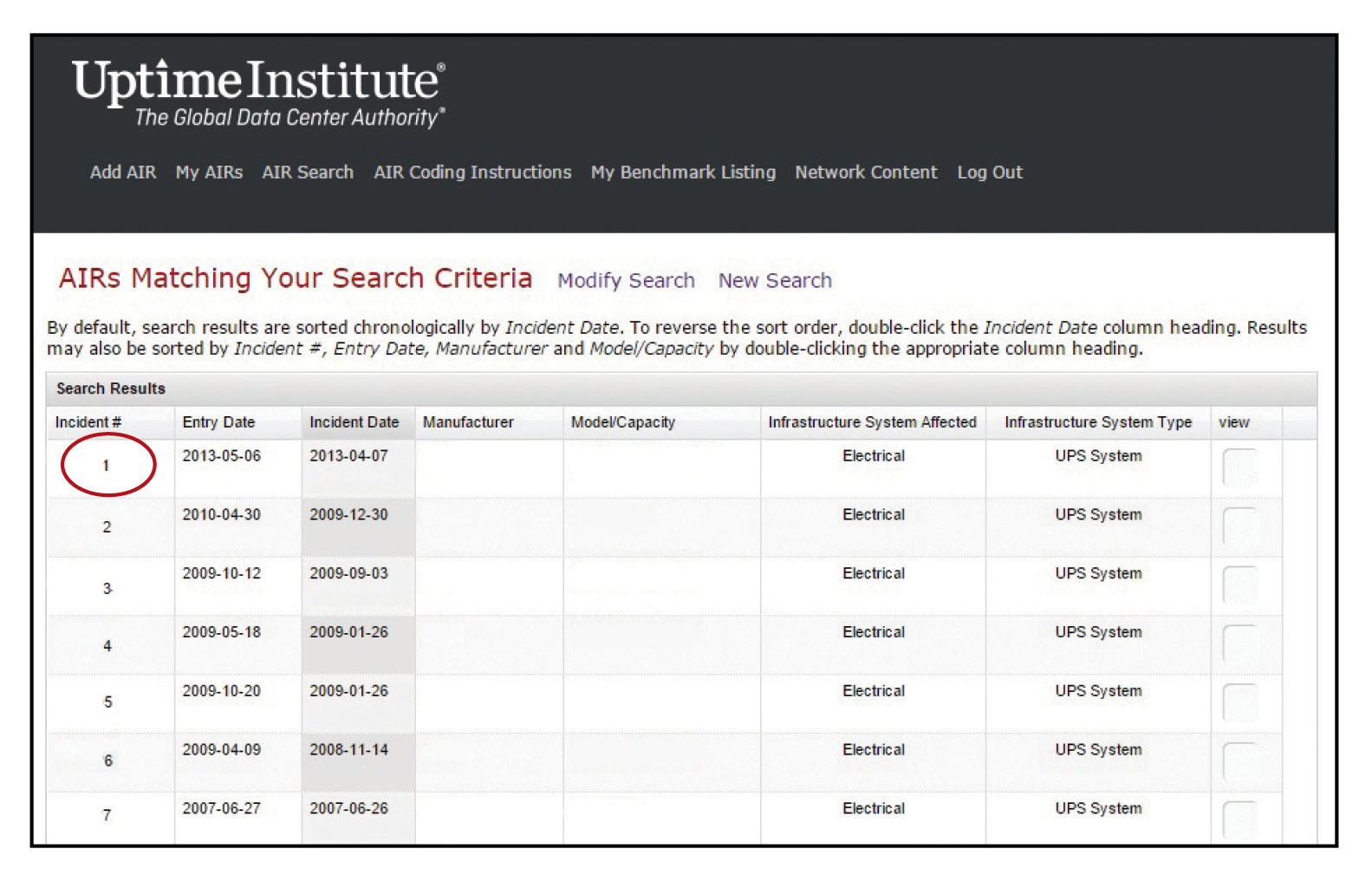
Figure 3. The results page of our search for incidents within the last 10 years (2005-2015) involving a specific manufacturer/model where there was a critical load loss. We selected the first result returned for further analysis.

Figure 4. The overview page of the abnormal incident report selected for detailed analysis.
The first incident report on the list (see Figure 4) reveals that the unit involved was built in 2008. A ventilation fan failed in the unit (a common occurrence for UPS modules of any manufacturer/model). Replacing the fan required technicians to implement a UPS maintenance bypass, which qualifies as a site configuration change. At this site, vendor personnel were permitted to perform site configuration changes. The UPS vendor technician was working in concert with one of the facility’s own operations engineers but was not being directly supervised (observed) at the time the incident occurred; he was out of the line of sight.
Social scientist Brené Brow said, “Maybe stories are just data with a soul.” If so, the narrative portion of each report is where we find the soul of the AIR (Figure 5). Drilling down into the story (Description, Action Taken, Final Resolution, and Synopsis) reveals what really happened, how the incident played out, and what the site did to address any issues. The detailed information found in these reports offers the richest value that can be mined for current and future operations. Reviewing this information yields insights and cautions and points towards prevention and solution steps to take to avoid (or respond to) a similar problem at other sites.

Figure 5. The detail page of the abnormal incident report selected for analysis. This is where the “story” of our incident is told.
In this incident, the event occurred when the UPS vendor technician opened the output breaker before bringing the module to bypass, causing a loss of power, and the load was dropped. This seemingly small but crucial error in communication and timing interrupted critical production operations—a downtime event.
Back-up systems and safeguards, training, procedures, and precautions, detailed documentation, and investments in redundant equipment—all are in vain the moment there is a critical load loss. The very rationale for the site having a UPS was negated by one error. However, this site’s hard lesson can be of use if other data center operators learn from the mistake and use this example to shore up their own processes, procedures, and incident training. Data center operators do not have to witness an incident to learn from it; the AIRs database opens up this history so that others may benefit.
As the incident unfolded, the vendor quickly reset the breaker to restore power, as instructed by the facility technician. Subsequently, to prevent this type of incident from happening in the future, the site:
• Created a more detailed method of procedure (MOP) for UPS maintenance
• Placed warning signs near the output breaker
• Placed switch tags at breakers
• Instituted a process improvement that now requires the presence of two technicians: an MOP supervisor and MOP performer, with both technicians required to verified each step
These four steps are Uptime Institute-recommended practices for data center operations. However, this narrative begs the question of how many sites have actually taken the effort to follow through on each of these elements, checked and double-checked, and drilled their teams to respond to an incident like this. Today’s operators can use this incident as a cautionary tale to shore up efforts in all relevant areas: operational documentation creation/improvement, planned maintenance process development/improvement, training, and PM program improvement.
Operational Documenation Creation/Improvement
In this hypothetical, the site added content and detail to its MOP for UPS maintenance. This can inspire other sites to review their UPS bypass procedures to determine if there is sufficient content and detail.
The consequences of having too little detail are obvious. Having too much content can also be a problem if it causes a technician to focus more on the document than on the task.
The AIR in this hypothetical did not say whether facility staff followed an emergency operating procedure (EOP), so there is not enough information to say whether they handled it correctly. This event may never happen in this exact manner again, but anyone who has been around data centers long enough knows that UPS output breakers can and will fail in a variety of unexpected ways. All sites should examine their EOP for unexpected failure/trip of UPS output breaker.
In this incident, the technician reclosed the breaker immediately, which is an understandable human reaction in the heat of the moment. However, this was probably not the best course of action. Full system start-up and shutdown should be orderly affairs, with IT personnel fully informed, if not present as active participants. A prudent EOP might require recording the time of the incident, following an escalation tree, gathering white space data, and confirming redundant equipment status, along with additional steps before undertaking a controlled, fully scripted restart.
Another response to failure was the addition of warning signs and improved equipment labeling as improvements to the facility’s site configuration procedures (SCPs). This change can motivate other sites to review their nomenclature and signage. Some sites include a document that gives expected or steady state system/equipment information. Other sites rely on labeling and warning signs or tools like stickers or magnets located beside equipment to indicate proper position. If a site has none of these safeguards in place, then assessment of this incident should prompt the site team to implement them.
Examining AIRs can provide specific examples of potential failure points, which can be used by other sites as a checklist of where to improve policies. The AIRs data can also be a spur to evaluate whether site policies match practices and ensure that documented procedures are being followed.
Planned Maintenance Process Improvement
After this incident, the site that submitted the AIR incident report changed its entire methodology for performing procedures. Now two technicians must be present, each with strictly defined roles: one technician reads the MOP and supervises the process, and the second technician verifies, performs, and confirms. Both technicians must sign off on the proper and correct completion of the task. It is unclear whether there was a change in vendor privileges.
When reviewing AIRs as a learning and improvement tool, facilities teams can benefit by implementing measures that are not already in place or any improvements that they determine they would implement if a similar incident had occurred at their site. For example, a site may conclude that configuration changes should be reserved only for those individuals who:
• Have a comprehensive understanding of site policy
• Have completed necessary site training
• Have more at stake for site performance and business outcomes
Training
The primary objective of site training is to increase adherence to site policy and knowledge of effective mission critical facility operations. Incorporating information gleaned from AIRs analysis helps maximize these benefits. Training materials should be geared to ensure that technicians are fully qualified to utilize their skills and abilities to operate the installed infrastructure within a mission critical environment and not to certify electricians or mechanics. In addition, training is an opportunity to provide an opportunity for professional development and interdisciplinary education amongst our operations team, which can help enterprises retain key personnel.
The basic components of an effective site-training program are an instructor, scheduled class times that can be tracked by student and instructor, on-the-job training (OJT), reference material, and a metric(s) for success.
With these essentials in place, the documentation and maintenance process improvement steps derived from the AIR incident report can be applied immediately for training. Newly optimized SOPs/MOPs/EOPs can be incorporated into the training, as well as process improvements such as the two-person rule. Improved documentation can be a training reference and study material, and improved SCPs will reduce confusion during OJT and daily rounds. Training drills can be created directly from real-world incidents, with outcomes not just predicted but also chronicled from actual events. Trainer development is enhanced by the involvement of an experienced technician in the AIR review process and creation of any resulting documentation/process improvement.
Combining AIRs data with existing resources enables sites to take a systematic approach to personnel training, for example:
1. John Doe is an experienced construction electrician who was recently hired. He needs UPS bypass training.
2. Jane Smith is a facility operations tech/operating engineer with 10 years of experience as a UPS technician. She was instrumental in the analysis of the AIRs incident and consequent improvements in the UPS bypass procedures and processes; she is the site’s SME in this area.
3. Using a learning management system (LMS) or a simple spreadsheet, John Doe’s training is scheduled.
• Scheduled Class: UPS bypass procedure discussion and walk-through
• Instructor: Jane Smith
• Student: John Doe
• Reference material: the new and improved UPS BYPASS SOP XXXX_20150630, along with the EOP and SCP
• Metric might include:
o Successful simulation of procedure as a performer
o Successful simulation of procedure as a supervisor
o Both of the above
o Successful completion of procedure during a PM activity
o Success at providing training to another technician
Drills for both new trainees and seasoned personnel are important. Because an AIRs-based training exercise is drawn from an actual event, not an imaginary scenario, it lends greater credibility to the exercise and validates the real risks. Anyone who has led a team drill has probably encountered that one participant who questions the premise of a procedure or suggests a different procedure. Far from being a roadblock to effective drills, the participant is proving to be actively engaged and can assist in program improvement by assisting in creating drills and assessing AIRs scenarios.
PM Program Improvement
The goal of any PM program is to prevent the failure of equipment. The incident detailed in the AIR incident report was triggered from a planned maintenance event, a UPS fan replacement. Typically, a fan replacement requires systems be put on bypass, as do annual PM procedures. Since any change of equipment configuration such as changing a fan introduces risk, it is worth asking whether predictive/proactive fan replacement performed during PM makes more sense than awaiting fan failure. The risk of configuration change must be weighed against the risk of inactivity.
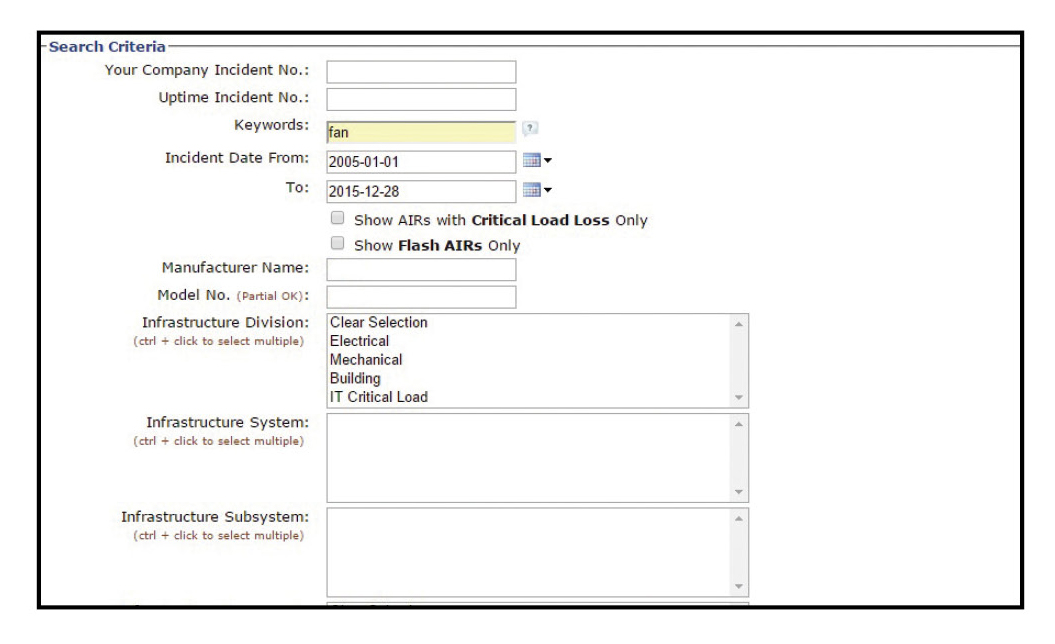
Figure 6. Our incident was not caused by UPS Fan Failure, but occurred as a result of human error during its replacement. So how many AIRs involving fan failures for our manufacturer/model of UPS exist within our database? Figure 6 shows the filters we chose to obtain this information.
Examining this and similar incidents in the AIRs database yields information about UPS fan life expectancy that can be used to develop an “evidence-based” replacement strategy. Start by searching the AIRs database for the keyword “fan” using the same dates, manufacturer, and model criteria, with no filter for critical load loss (see Figure 6). This search returns eight reports with fan failure (see Figure 7). The data show that the average life span of the units with fan failure was 5.5 years. The limited sample size means that this result should not be relied on, but this experience at other sites can help guide planning. Less restrictive search criteria can return even more specific data.
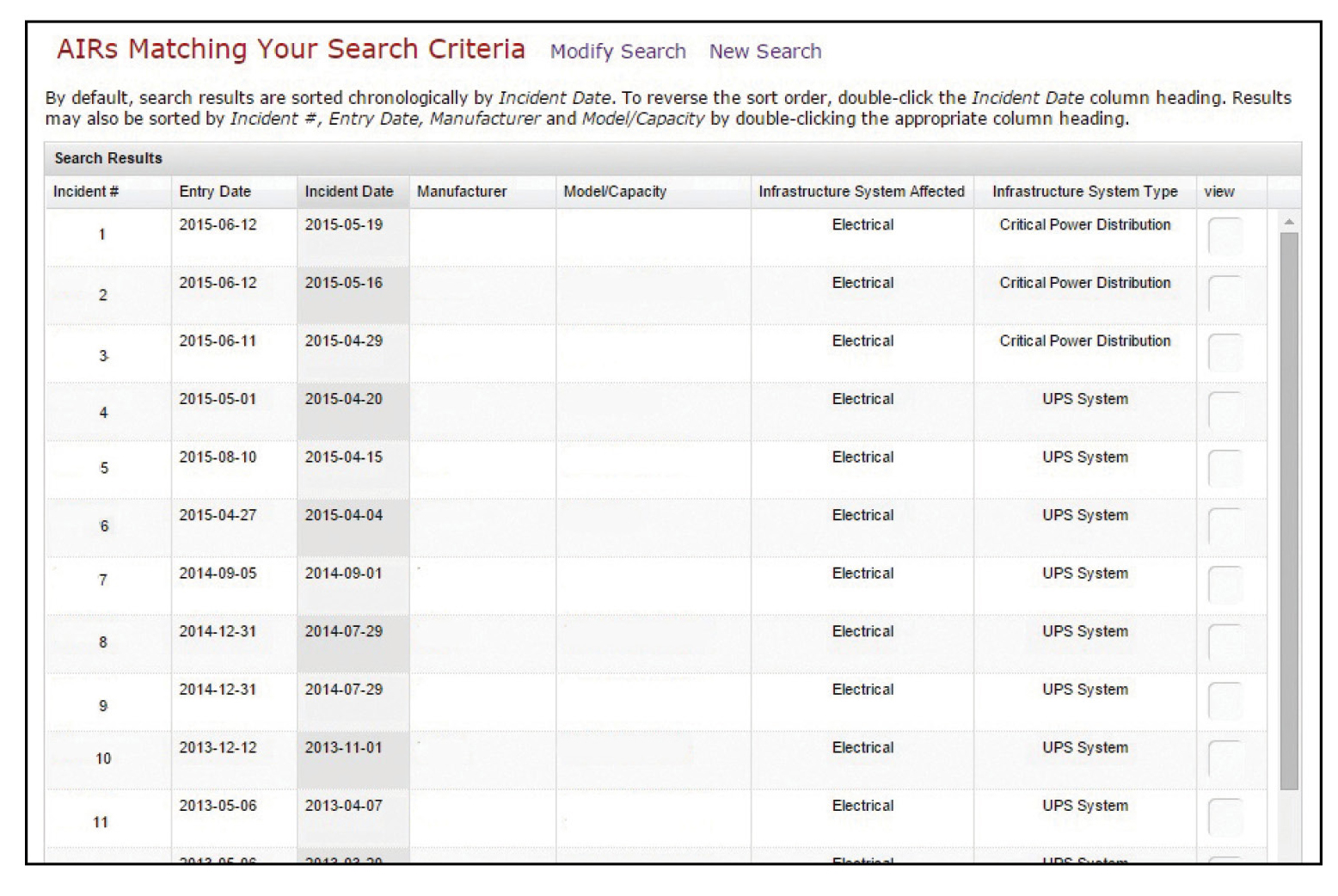
Figure 7. A sample of the results (showing 10 of 25 results reports) returned from the search described in Figure 6. Analysis of these incidents may help us to determine and develop the best strategy for cooling fan replacement.
Additional Incidents Yield Additional Insight
The initial database search at the start of this hypothetical case returned a result of seven AIRs total. What can we learn from the other six? Three of the remaining six reports involved capacitor failures. At one site, the capacitor was 12 years old, and the report noted, “No notification provided of the 7-year life cycle by the vendor.” Another incident occurred in 2009, involving a capacitor with a 2002 manufacture date, which would match (perhaps coincidentally) a 7-year life cycle. The third capacitor failure was in a 13-year old piece of equipment, and the AIR notes that it was “outside of 4–5-year life cycle.” These results highlight the importance of having an equipment/component life-cycle replacement strategy. The AIRs database is a great starting point.
A fourth AIR describes a driver board failure in a 13-year old UPS. Driver board failure could fall into any of the AIR root-cause types. Examples of insufficient maintenance might include a case where maintenance performed was limited in scope and did not consider end-of-life. Perhaps there was no procedure to diagnose equipment for a condition or measurement indicative of component deterioration, or maybe maintenance frequency was insufficient. Without further data in the report it is hard to draw an actionable insight, but the analysis does raise several important topics for discussion regarding the status of a site’s preventive and predictive maintenance approach. A fifth AIR involves an overload condition resulting from flawed operational documentation. The lesson there is obvious.
The final of the remaining six reports resulted from a lightning strike that made it through the UPS to interrupt the critical load. Other sites might want to check transient voltage surge suppressor (TVSS) integrity during rounds. With approximately 138,000,000 lightning strikes per year worldwide, any data center can be hit. A site can implement an EOP that dictates checking summary alarms, ensuring redundant equipment integrity, performing a facility walk-through by space priority, and providing an escalation tree with contact information.
Each of the AIRs casts light on the types of shortfalls and gaps that can be found in even the most capably run facilities. With data centers made up of vast numbers of components and systems operating in a complex interplay, it can be difficult to anticipate and prevent every single eventuality. AIRs may not provide the most definitive information on equipment specifications, but assessing these incidents provides an opportunity for other sites to identify potential risks and plan how to avoid them.
PURCHASING/EQUIPMENT PROCUREMENT DECISIONS
In addition to the operational uses described above, AIRs information can also support effective procurement. However, as with using almost any type of aggregated statistics, one should be cautious about making broad assumptions based on the limited sample size of the AIRs database.
For example, a search using simply the keywords ‘fan failure’ and ‘UPS’ could return 50 incidents involving Vendor A products and five involving Vendor B’s products (or vice versa). This does not necessarily mean that Vendor A has a UPS fan failure problem. The number of incidents reported could just mean that Vendor B has a significant market share advantage.
Further, one must be careful of jumping to conclusions regarding manufacturing defects. For example, the first AIR incident report made no mention of how the UPS may (or may not) have been designed to help mitigate the risk of the incident. Some UPS modules have HMI (human machine interface) menu-driven bypass/shutdown procedures that dictate action and provide an expected outcome indication. These equipment options can help mitigate the risk of such an event but may also increase the unit cost. Incorporating AIRs information as just one element in a more detailed performance evaluation and cost-benefit analysis will help operators accurately decide which unit will be the best fit for a specific environment and budget.
LEARNING FROM FAILURES
If adversity is the best teacher, then every failure in life is an opportunity to learn, and that certainly applies in the data center environment and other mission critical settings. The value of undertaking failure analysis and applying lessons learned to continually develop and refine procedures is what makes an organization resilient and successful over the long term.
To use an example from my own experience, I was working one night at a site when the operations team was transferring the UPS to maintenance bypass during PM. Both the UPS output breaker and the UPS bypass breaker were in the CLOSED position, and they were sharing the connected load. The MOP directed personnel to visually confirm that the bypass breaker was closed and then directed them to open the UPS output breaker. The team followed these steps as written, but the critical load was dropped.
Immediately, the team followed EOP steps to stabilization. Failure analysis revealed that the breaker had suffered internal failure; although the handle was in the CLOSED position, the internal contacts were not closed. Further analysis yielded a more detailed picture of events. For instance, the MOP did not require verification of the status of the equipment. Maintenance records also revealed that the failed breaker had passed primary injection testing within the previous year, well within the site-required 3-year period. Although meticulous compliance with the site’s maintenance standards had eliminated negligence as a root cause, the operational documentation could have required verification of critical component test status as a preliminary step. There was even a dated TEST PASSED sticker on the breaker.
Indeed eliminating key gaps in the procedures would have prevented the incident. As stated, the breaker appeared to be in the closed position as directed, but the team had not followed the load during switching activities, (i.e., had not confirmed the transfer of the amperage to the bypass breaker). If we had done so, we would have seen a problem, and initiated a back-out of the procedure. Subsequently, these improvements were added to the MOP.
FLASH REPORTS
Flash reports are a particularly useful AIRs service because they provide early warning about incidents identified as immediate risks, with root causes and fixes to help Network members prevent a service interruption. These reports are an important source of timely front-line risk information.
For example, searching the AIRs database for any FLASH AIR since 2005 involving one popular UPS model returns two results. Both reports detailed a rectifier shutdown as a result of faulty trap filter components; The vendor consequently performed a redesign and recommended a replacement strategy. The FLASH report mechanism became a crucial channel for communicating the manufacturer’s recommendation to equipment owners. Receiving a FLASH notification can spur a team to check maintenance records and consult with trusted vendors to ensure that manufacturer bulletins or suggested modifications have been addressed.
When FLASH incidents are reported, Uptime Institute’s AIRs program team contacts the manufacturer as part of its validation and reporting process. Uptime Institute strives for and considers its relationships with OEMs (original equipment manufacturers) to be cooperative, rather than confrontational. All parties understand that no piece of complex equipment is perfect, so the common goal is to identify and resolve issues as quickly and smoothly as possible.
CONCLUSION
It is virtually impossible for an organization’s site culture, procedures, and processes to be so refined that there are no details left unaddressed and no improvements that can be made. There is also a need to beware of hidden disparities between site policy and actual practice. Will a team be ready when something unexpected does go wrong? Just because an incident has not happened yet does not mean it will not happen. In fact, if a site has not experienced an issue, complacency can set in; steady state can get boring. Operators with foresight will use AIRs as opportunities to create drills and get the team engaged with troubleshooting and implementing new, improved procedures.
Instead of trying to ferret out gaps or imagine every possible failure, the AIRs database provides a ready source of real-world incidents to draw from. Using this information can help hone team function and fine tune operating practices. Technicians do not have to guess at what could happen to equipment but can benefit from the lessons learned by other sites. Team leaders do not have to just hope that personnel are ready to face a crisis; they can use AIRs information to prepare for operating eventualities and to help keep personnel responses sharp.
AIRs is much more than a database; it is a valuable tool for raising awareness of what can happen, mitigating the risk that it will happen, and for preparing an operations team for when/if it does happen. With uses that extend to purchasing, training, and maintenance activities, the AIRs database truly is Uptime Institute Network members’ secret weapon for operational success.

Ron Davis
Ron Davis is a Consultant for Uptime Institute, specializing in Operational Sustainability. Mr. Davis brings more than 20 years of experience in mission critical facility operations in various roles supporting data center portfolios, including facility management, management and operations consultant, and central engineering subject matter expert. Mr. Davis manages the Uptime Institute Network’s Abnormal Incident Reports (AIRs) database, performing root-cause and trending analysis of data center outages and near outages to improve industry performance and vigilance.


 2020
2020

 2020
2020
