 UI 2021
UI 2021Network problems causing ever more outages
Power failures have always been one of the top causes of serious IT service outages. The loss of power to a data center can be devastating, and its consequences have fully justified the huge expense and effort that go into preventing such events.
But in recent years, other causes are catching up, with networking issues now emerging as one of the more common — if not the most common — causes of downtime. In our most recent survey of nearly 300 data center and IT service operators, network issues were cited as the most common reason for any IT service outage — more common even than power problems (see Figure 1).
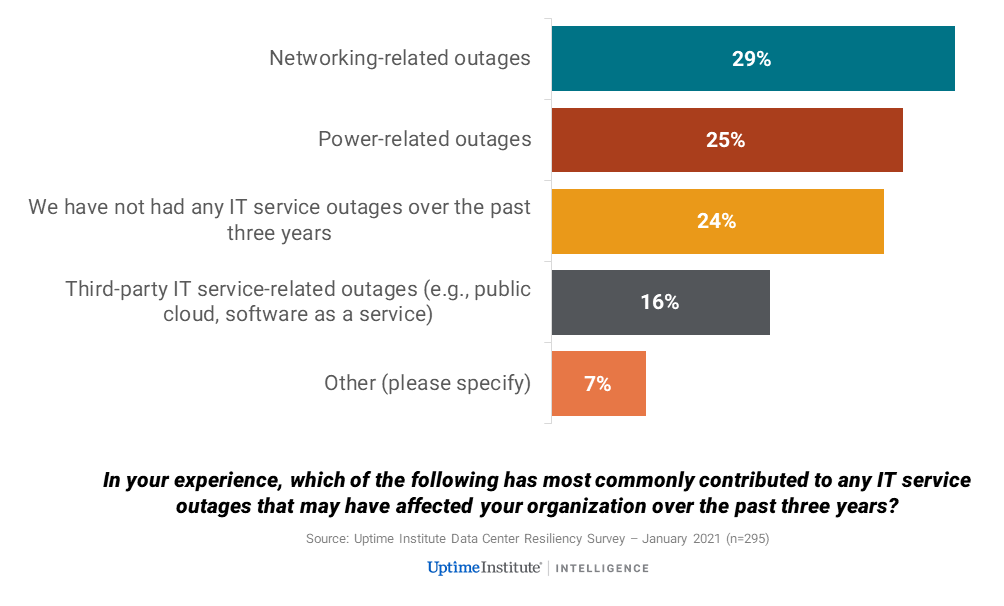
Figure 1. Among survey respondents, networking issues were the most common cause of IT service outages in the past three years.
The reasons are clear enough: modern applications and data are increasingly spread across and among data centers, with the network ever more critical. To add to the mix, software-defined networks have added great flexibility and programmability, but they have also introduced failure-prone complexity.
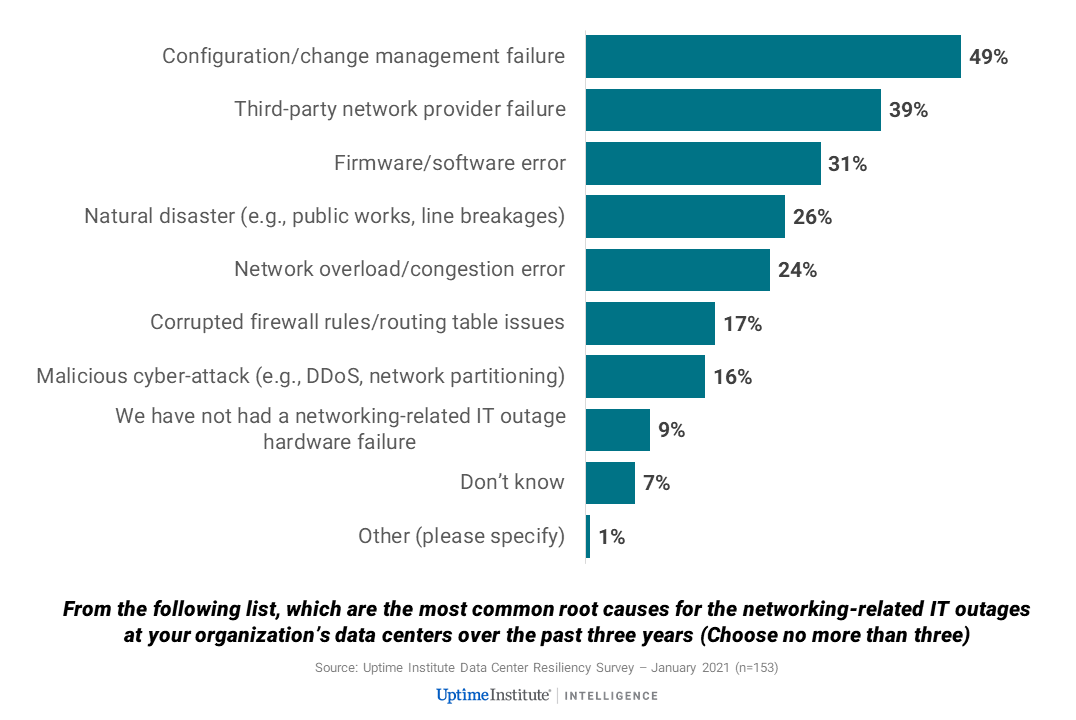
Delving a little deeper confirms the complexity diagnosis. Configuration errors, firmware errors, and corrupted routing tables all play a big role, while the more traditional worries of weather and cable breaks are a relatively minor concern. Congestion and capacity issues also cause failures, but these are often themselves the result of programming/configuration issues.
Networks are complex not only technically, but also operationally. While enterprise data centers may be served by only one or two providers, multi-carrier colocation hubs can be served by many telecommunications providers. Some of these links may, further down the line, share cables or facilities — adding possible overlapping points of failure or capacity pinch points. Ownership, visibility and accountability can also be complicated. These factors combined help account for the fact that 39% of survey respondents said they had experienced an outage caused by a third-party networking issue — something over which they had little control (see Figure 2).
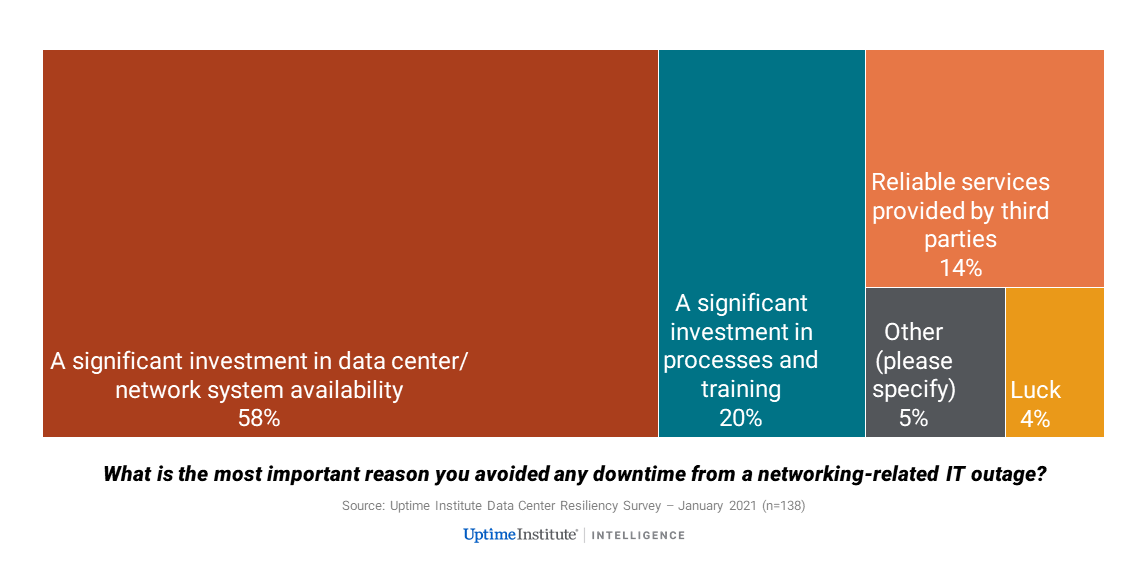
Among those who avoided any downtime from networking-related outages, what was the most important reason why?
A few of those organizations that avoided any network-related downtime put this down to luck (!). (We know of one operator who suffered two separate, unrelated critical cable breaks at the same time.) But the majority of those who avoided downtime credited a factor that is more controllable: investment in systems and training (see Figure 3).
The Bottom Line: As with the prevention of power issues, money spent on expertise, redundancy, monitoring, diagnostics and recovery — along with staff training and processes — will be paid back with more hours of uptime.









 UI 2021
UI 2021